Introduction
Wasm (WebAssembly) is a virtual instruction set that can be executed in modern major browsers.
It has the following main features:
- Can be executed in major browsers
- Not dependent on OS or CPU
- Runs in a secure sandbox environment
- Provides performance close to native1
- Can be compiled from multiple languages (Rust, Go, C, etc.)
With a Runtime environment, Wasm binaries can be executed not only in browsers but also on the server-side. For example, Wasm can be adopted in an application's plugin system or utilized in serverless application development.
The interest in Wasm, which is expected to continue to grow, is likely shared by many who are curious about its operation principles. In this document, after introducing Wasm and explaining its use cases, we aim to understand the operational principles by implementing a small Runtime from scratch using Rust to output Hello World.
Even though understanding a small Runtime may require some effort, we will explain each aspect step by step, so let's proceed together without rushing.
Things you need to understand for the small Runtime include:
- Understanding the data structure of Wasm binaries
- Understanding the instruction set of Wasm used
- Understanding the mechanism of instruction processing
- Implementing Wasm binary decoding
- Implementing instruction processing
By the way, the Runtime to be implemented adheres to the specifications of version 1 (specification). The specification may be challenging to read, but for those interested, we encourage you to continue implementing based on the explanations provided in this document.
Target Audience
The target audience of this document is as follows:
- Those who understand the basics of Rust and can read and write in it
- Those interested in Wasm
- Those who want to understand how Wasm is executed
Glossary
The terms used in this document are as follows:
- Wasm Abbreviation for WebAssembly Refers to the entire ecosystem
- Wasm binary
Refers to
*.wasmfiles Contains bytecode - Wasm Runtime
Environment that can execute Wasm, also known as an interpreter
This document will implement a Runtime that can read and execute
*.wasmfiles - Wasm Spec Refers to the specifications of Wasm This document adheres to the specifications of version 1
About This Document
The manuscript of this document is available in this repository, so if you find any confusing parts or strange explanations, please submit a pull request.
About the Author
Strictly depends on the implementation of the Runtime
Overview of Wasm
In this chapter, we will mainly explain the following about Wasm:
- Overview of Wasm Runtime
- Pros and Cons of Wasm
- Use cases of Wasm
Overview of Wasm Runtime
As mentioned in the previous chapter, Wasm is a virtual instruction set. The Wasm Runtime, which reads and executes these virtual instructions, is essentially a virtual machine itself.
When we talk about virtual machines, we can think of Java VM or RubyVM, and Wasm Runtime falls into the same category. Java and Ruby compile source code to generate bytecode, which is then executed by the virtual machine. Similarly, Wasm follows a similar process.
However, as shown in Figure 1, a notable feature of Wasm is its ability to be compiled from various languages such as C, Go, and Rust.
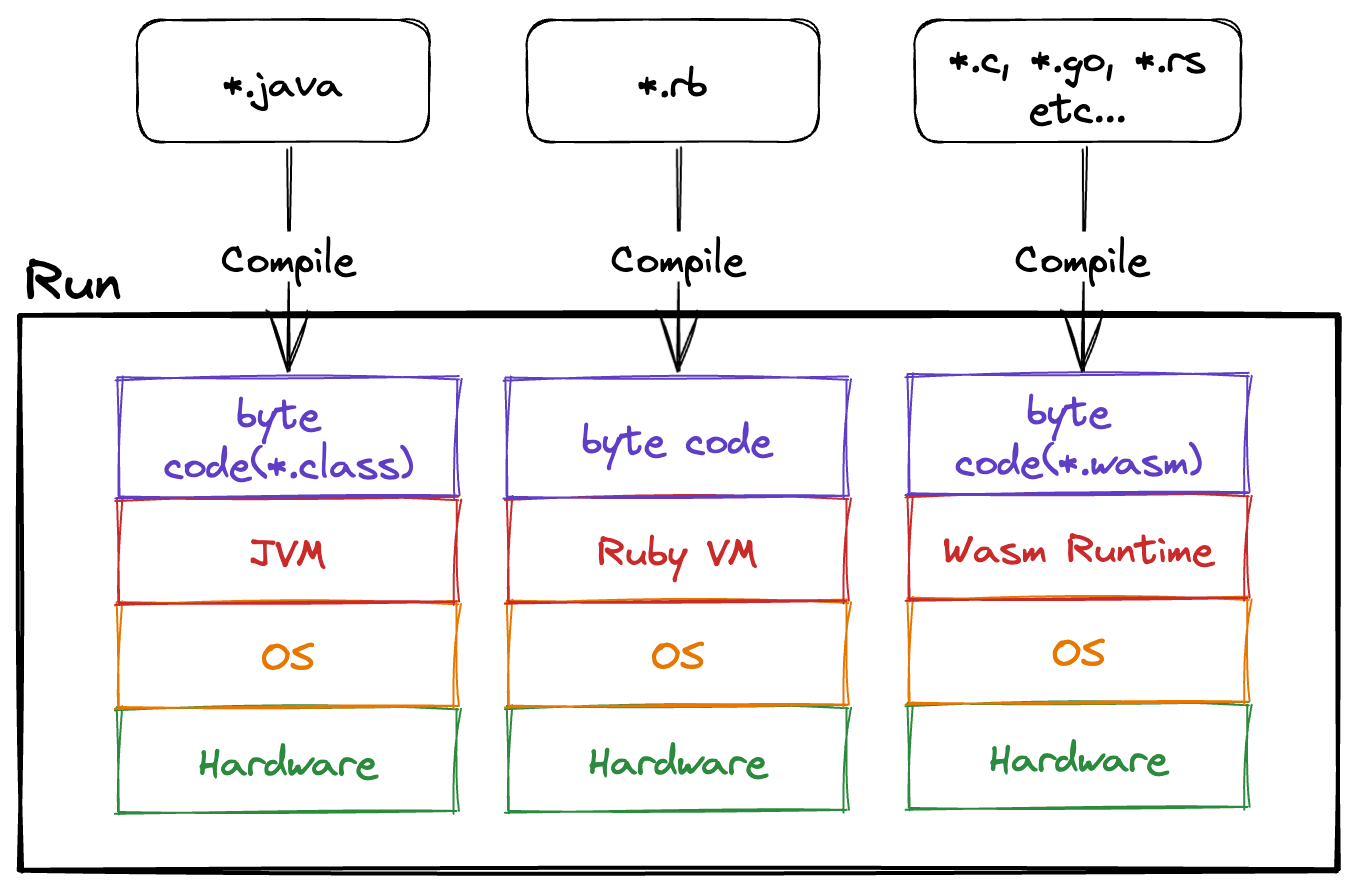 Figure 1
Figure 1
This book will essentially implement a virtual machine similar to Java VM or RubyVM. The Wasm Runtime itself is not very complex, capable of performing numerical calculations and memory operations that it possesses.
One might wonder if tasks like standard output are possible. In fact, resource operations (such as file or network operations) are not included in the Wasm Spec but are part of the WebAssembly System Interface (WASI) specification. WASI consists of a collection of POSIX-like system call functions, allowing resource operations by calling these functions.
For this instance, we will implement the fd_write function of WASI to output Hello World.
Pros and Cons of Wasm
The author's perspective on the pros and cons of Wasm are as follows.
Pros
- Secure Execution
Without using WASI, Wasm Runtime generally does not have an impact outside the runtime, making it a kind of sandbox environment.
For example, it is secure as it cannot extract confidential information from environment variables. - Portability
Wasm is independent of the OS and CPU, allowing execution anywhere with a runtime.
It can be executed in major browsers like Google Chrome, Firefox, and Microsoft Edge.
Besides major browsers, there are runtimes like Wasmtime and wazero for server-side execution. - Language Diversity
Wasm can be compiled from multiple languages, enabling the utilization of assets from various languages.
Additionally, it can import other Wasm binaries, facilitating the sharing of language assets across language barriers.
Cons
- Lack of Support in Older Browsers
Although rare, older browsers may not support Wasm, leading to the inability to execute Wasm binaries.
In such cases, using a library like polywasm can enable running Wasm. - Evolving Technology
Wasm is a relatively new technology, with ongoing specification extensions alongside WASI.
As a result, the ecosystem is still maturing, making it challenging to build full-fledged applications solely with Wasm. - Performance Depends on Runtime
Performance differences can arise based on the implementation of the runtime.
For instance, executing in Chrome and Wasmtime involves different runtimes, necessitating consideration of this aspect in benchmark comparisons.
When comparing the execution speed of Wasm binaries, measurements should be done with the same runtime, and when measuring runtime speed, it should be done with the same Wasm binary.
Use Cases of Wasm
We will introduce several examples of scenarios where Wasm is being utilized.
Plugin Systems
Due to Wasm's ability to be compiled from multiple languages, it is often adopted in building plugin mechanisms. For example, the terminal multiplexer called zellij utilizes Wasm. For more details, refer to this link.
In addition, the Envoy Proxy server also provides a mechanism for extending functionality using Wasm.
Serverless Applications
By using the spin framework, you can build serverless applications with Wasm. In addition to spin, there are other options such as wasmCloud and Wasmer Edge.
Containers
In addition to Linux containers in Docker and Kubernetes, you can also use Wasm. To explain how Docker and Kubernetes run Linux containers and Wasm, an overview is provided based on Figure 2.
![]() Figure 2
Figure 2
containerd- Manages container images (such as retrieval and deletion) and operations on containers (such as creation and start)
- Also known as a high-level container runtime
runc- Actually creates and starts Linux containers
- Also known as a low-level container runtime
containerd-shim- Bridges
containerdandrunc - Essentially just an execution binary
- Bridges
containerd-shim-*- Bridges
containerdandWasm Runtime - Essentially just an execution binary
- There are execution binaries like
containerd-shim-wasmtimeandcontainerd-shim-wasmedge - When implementing
containerd-shim-*in Rust, use runwasi
- Bridges
Summary
This chapter provides a brief introduction to the Wasm Runtime and the ecosystem using Wasm. In the next chapter, we will actually use Wasm with Wasmtime.
Assumes that the Runtime implementation is free of vulnerabilities.
Introduction to Wasm
This chapter will use a language that can be compiled into Wasm binary called WAT (WebAssembly Text Format) to experience running Wasm in practice.
For a detailed explanation of WAT, refer to the very clear explanation in MDN's Understanding the text format of WebAssembly. Once you have a good understanding up to "First Function Body," you should generally have no trouble following the explanations in the rest of this chapter.
Environment
This document will explain using the following environment:
- OS: macOS Ventura
- CPU: Apple M1 Pro (ARM64)
Prerequisites
Installing wabt
First, install a toolset called wabt. Below are the installation steps using Homebrew on macOS, but for installation methods on platforms other than macOS, please refer to the repository.
$ brew install wabt
In this chapter, we will use wat2wasm to convert WAT to Wasm binary.
The version at the time of writing is as follows.
$ wat2wasm --version
1.0.33
Installing Wasmtime
To execute compiled Wasm binaries, install Wasmtime. Below are the installation steps for macOS and Linux, but for installation on Windows, please refer to the official documentation.
$ curl https://wasmtime.dev/install.sh -sSf | bash
The version at the time of writing is as follows.
$ wasmtime --version
wasmtime-cli 12.0.1
Trying to Execute a Wasm Binary
First, create an add.wat file and paste the following code.
This code defines a function that takes two arguments and returns the result of their addition.
(module
(func (export "add") (param $a i32) (param $b i32) (result i32)
(local.get $a)
(local.get $b)
i32.add
)
)
Next, use wat2wasm to output the Wasm binary and execute it using wasmtime.
wat2wasm is a CLI that compiles WAT to Wasm binary.
# Compile
$ wat2wasm add.wat
$ ls
add.wasm
add.wat
# Execute function
$ wasmtime add.wasm --invoke add 1 2
warning: using `--invoke` with a function that takes arguments is experimental and may break in the future
warning: using `--invoke` with a function that returns values is experimental and may break in the future
3
Supplement on Stack Machine
Although MDN explains the stack machine, I felt it was slightly lacking, so here is a supplement. Looking at the instruction list of the code we used earlier, it appears as follows:
(local.get $a)
(local.get $b)
i32.add
Here, local.get pushes the value of the argument onto the stack, and i32.add pops two values from the stack, adds them, and pushes the result back onto the stack.
When the function returns to the caller, if there is a return value, it is popped from the stack.
In pseudo-Rust code, this would look something like:
#![allow(unused)] fn main() { // Stack to store values to process let mut stack: Vec<i32> = vec![]; // Area to hold function local variables let mut locals: Vec<i32> = vec![]; // A loop that processes instructions loop { let instruction = fetch_inst(); match instruction { inst::LocalGet => { let value = locals.pop(); stack.push(value); } inst::I32Add => { let right = stack.pop(); let left = stack.pop(); stack.push(left + right); } ... } } return stack.pop(); }
In this way, the Wasm Runtime performs very simple calculations using a stack machine.
The actual implementation is more complex, but fundamentally, it repeats the process as described above.
Summary
In this chapter, we briefly ran Wasm and touched on the implementation using pseudo code. While most explanations about WAT are deferred to MDN, which is much clearer than what the author could write, if you are unsure, please revisit it repeatedly.
The next chapter will explain the structure of Wasm binaries as preparation before implementing the Wasm Runtime.
Wasm binary structure
When the Wasm Runtime executes a Wasm binary, there are two main steps: decoding the Wasm binary and processing instructions. To decode the binary, it is necessary to understand the structure of the binary, so this chapter will explain that structure.
By the end of this chapter, you will understand what the structure of the binary looks like.
Overview of Wasm Binary
A Wasm binary consists of an 8-byte preamble at the beginning, followed by various sections.
The preamble consists of the Magic Number '\0asm' and the version value 1, each occupying 4 bytes at the beginning of the file.
The following is a modified output of a binary generated by wat2wasm -v, with some additional explanations.
\0asm
┌───┴───┐
0000000: 0061 736d ; WASM_BINARY_MAGIC
~~~~~~~ ~~ ~~~~~~~~~~~~~~~~~~~~
│ │ │
│ │ └ Comment
│ └ Hexadecimal notation, 2 digits = 1 byte
└ Offset of address
0000004: 0100 0000 ; WASM_BINARY_VERSION
In the explanations of the binary structure that follow, we will generally use this output with some added clarity.
There are multiple sections, each storing information necessary for execution at runtime. For example, there is information about function signatures, memory initialization, and instructions to be executed.
It is worth noting that sections are optional, so it is possible to create a minimal Wasm binary consisting only of the preamble.
In this document, we will implement the following sections, so for other sections, please refer to the specification.
| Section | Description |
|---|---|
Type Section | Information about function signatures |
Code Section | Information about instructions per function |
Function Section | Reference information to function signatures |
Memory Section | Information about linear memory |
Data Section | Information about data to be placed in memory during initialization |
Export Section | Information about exporting to other modules |
Import Section | Information about importing from other modules |
Subsequently, we will explain the data structures of each section.
Type Section
An area that holds function signature information. In brief, a signature refers to the type of a function.
A function signature is uniquely determined by the following combination:
- Types and order of arguments
- Types and order of return values
For example, functions $a and $b in List 1 have differences in argument order and presence of return values, so they have different signatures, but $a and $c have the same signature.
Signatures essentially define the input and output of a function, independent of the function's content, so $a and $c will reference the same signature information.
List 1
(module
(func $a (param i32 i64))
(func $b (param i64 i32) (result i32 i64)
(local.get 1)
(local.get 0)
)
(func $c (param i32 i64))
)
Function signatures provide information on how many arguments and return values to push onto the stack when executing a function.
The detailed usage of signature information will be explained in the chapter on Runtime implementation.
List 2 represents the binary structure.
List 2
; section "Type" (1)
0000008: 01 ; section code
0000009: 0d ; section size
000000a: 02 ; num types
; func type 0
000000b: 60 ; func
000000c: 02 ; num params
000000d: 7f ; i32
000000e: 7e ; i64
000000f: 00 ; num results
; func type 1
0000010: 60 ; func
0000011: 02 ; num params
0000012: 7e ; i64
0000013: 7f ; i32
0000014: 02 ; num results
0000015: 7f ; i32
0000016: 7e ; i64
The first 2 bytes represent the section code and section size, which are common to all sections.
Although they do not have an official name, we will refer to them as section headers in this document.
; section "Type" (1)
0000008: 01 ; section code
0000009: 0d ; section size
000000a: 02 ; num types
The section code is a unique value used to identify the section, with 1 representing the Type Section.
The section size indicates the number of bytes in the section data excluding the first 2 bytes.
This helps determine how much of the binary needs to be read when decoding the section.
num types represents the number of function signatures. For each of these, the function signatures will be decoded.
The remaining part of the section defines function signatures. Each function signature starts with 0x60 and is defined in the order of the number and types of arguments, followed by the number and types of return values.
In List 3, func type 0 contains the signature information of (func $a (param i32 i64)) and (func $c (param i32 i64)), while func type 1 contains the signature information of (func $b (param i64 i32) (result i32 i64)).
List3
; func type 0
000000b: 60 ; func ┐
000000c: 02 ; num params │ (func $a (param i32 i64))
000000d: 7f ; i32 ├ (func $c (param i32 i64))
000000e: 7e ; i64 │
000000f: 00 ; num results ┘
; func type 1
0000010: 60 ; func ┐
0000011: 02 ; num params │
0000012: 7e ; i64 │ (func $b
0000013: 7f ; i32 ├ (param i64 i32)
0000014: 02 ; num results │ (result i32 i64)
0000015: 7f ; i32 │ )
0000016: 7e ; i64 ┘
Decoding function signatures generally involves the following steps:
- Read 1 byte and verify if it is
0x60. - Read 1 byte to obtain the number of arguments.
- Read the bytes corresponding to the number obtained in step 2. For example, if it is 2, read 2 bytes.
- Read through the bytes obtained in step 3 one by one to get the type information corresponding to the values (e.g., if
0x7e, it represents the i64 type). - Obtain the return value type information following steps 2 to 4.
Code Section
The Code Section primarily stores the instruction information of functions.
List 4 represents the binary structure of the Code Section.
List4
; section "Code" (10)
000001d: 0a ; section code
000001e: 0e ; section size
000001f: 03 ; num functions
; function body 0
0000020: 02 ; func body size
0000021: 00 ; local decl count
0000022: 0b ; end
; function body 1
0000023: 06 ; func body size
0000024: 00 ; local decl count
0000025: 20 ; local.get
0000026: 01 ; local index
0000027: 20 ; local.get
0000028: 00 ; local index
0000029: 0b ; end
; function body 2
000002a: 02 ; func body size
000002b: 00 ; local decl count
000002c: 0b ; end
num functions indicates the number of functions, and you decode functions based on this number.
The remaining part consists of the definitions of local variables and instruction information for each function, which need to be decoded iteratively.
func body size indicates the number of bytes in the function body.
local decl count indicates the number of local variables.
If it is 0, no action is taken, but if it is greater than 1, the subsequent byte sequence defines the types of local variables.
The byte sequence up to end represents the function instructions, and the Runtime processes these instructions.
Decoding functions generally involves the following steps:
- Read 1 byte to obtain the size of the function.
- Read the byte sequence corresponding to the function size obtained in step 1.
- Read 1 byte to obtain the number of local variables.
- Read through the bytes obtained in step 3 one by one to get the type information.
- Obtain the instructions until the byte sequence read in step 2 is exhausted.
Function Section
The Function Section holds information that links function bodies (Code Section) with type information (Type Section).
List 5 represents the binary structure.
List5
; section "Function" (3)
0000017: 03 ; section code
0000018: 04 ; section size
0000019: 03 ; num functions
000001a: 00 ; function 0 signature index
000001b: 01 ; function 1 signature index
000001c: 00 ; function 2 signature index
The value of function x signature index represents the index information (0-based) to the function signature.
For example, function 2 indicates that it has the signature 0 from the Type Section.
To clarify the relationship, refer to Figure 1.

Figure 1
Memory Section
The Memory Section stores information on how much memory to allocate for the Runtime.
Memory can be extended in page units, with 1 page being 64KiB as specified in the specification.
Memory is formatted as (memory $initial $max) as shown in List 6, where 2 represents the initial memory page count, and 3 represents the maximum page count.
max is optional, and if not specified, there is no upper limit.
List6
(module
(memory 2 3)
)
The binary structure is represented as shown in List 7.
List7
; section "Memory" (5)
0000008: 05 ; section code
0000009: 04 ; section size
000000a: 01 ; num memories
; memory 0
000000b: 01 ; limits: flags
000000c: 02 ; limits: initial
000000d: 03 ; limits: max
num memories indicates the number of memories, but in version 1 of the specification, only one memory can be defined per module, making this value effectively fixed at 1.
limits: flags is a value used to determine whether max exists, meaning that if it is 0, only initial exists, and if it is 1, both initial and max exist. This allows you to understand how to decode it.
Data Section
The Data Section is the area where data to be placed after memory allocation in the Runtime is defined. In other words, it defines the initial data of the memory.
List 8 is an example defining the string Hello, World!\n in memory.
List 8
(module
(memory 1)
(data 0 (i32.const 0) "Hello, World!\n")
)
The data is formatted as (data $memory $offset $data) and consists of the following elements:
$memoryis the index of the memory where the data is placed$offsetis the instruction sequence to calculate the offset of the memory to place the data$datais the actual data to be placed in memory
In this example, the string Hello, World!\n is placed in the 0th byte of the 0th memory.
The binary structure is as shown in List 9.
List 9
; section "Data" (11)
000000d: 0b ; section code
000000e: 14 ; section size
000000f: 01 ; num data segments
; data segment header 0
0000010: 00 ; segment flags
0000011: 41 ; i32.const
0000012: 00 ; i32 literal
0000013: 0b ; end
0000014: 0e ; data segment size
; data segment data 0
0000015: 4865 6c6c 6f2c 2057 6f72 6c64 210a ; data segment data
The data is organized into units called segments, and there may be multiple segments. A segment consists of header and data areas, where header contains the instruction sequence to calculate the offset and data holds the actual data.
num data segments is the number of segments.
The data segment header is the area that holds metadata such as the memory where the data is placed and the offset. There is one for each segment.
segment flags indicate the index of the memory where the data is placed. In version 1, only one memory can be defined, so it is effectively fixed at 0.
From i32.const to end is the instruction sequence to calculate the offset. In this case, only fixed values are handled, but global values can also be referenced.
data segment size is the length of the actual data to be placed, and data segment data is the actual data to be placed in memory.
Figure 2 illustrates the structure of the segment in List 9.

Figure 2
Export Section
The Export Section is the area where information accessible from other modules is defined. In version 1, memories, functions, etc., can be exported.
On the Runtime side, only exported functions can be called, so if, for example, a function to perform addition needs to be called from the Runtime, the function must be exported.
List 10 is an example of exporting the function $dummy that the module itself has as dummy.
List 10
(module
(func $dummy)
(export "dummy" (func $dummy))
)
The export format is (export $name ($type $index)). $name is the name to be exported, $type is the type of data to be exported such as func or memory, and $index is the index or name of that data. For example, in the case of func 0, it refers to the 0th function. In this example, the function name $dummy is specified, but it will be converted to an index when it becomes binary.
The binary structure is as shown in List 11.
List 11
; section "Export" (7)
0000012: 07 ; section code
0000013: 09 ; section size
0000014: 01 ; num exports
0000015: 05 ; string length
0000016: 6475 6d6d 79 ; export name (dummy)
000001b: 00 ; export kind
000001c: 00 ; export func index
num exports is the number of data to be exported.
string length is the length of the byte sequence of the exported name, and export name is the actual byte sequence of characters.
export kind is the type of data, where for memory it is 0x02.
export func index is the index of the function to be exported.
Import Section
Import Section is an area where information is defined to import entities such as memory and functions that exist outside the module. The term "outside the module" refers to memory and functions provided by other modules or the Runtime.
In this case, we are implementing WASI, and the actual implementation of WASI functions is done on the Runtime side, so we plan to import and use them.
List 12 is an example of importing a function named add from a module called adder.
List 12
(module
(import "adder" "add" (func (param i32 i32) (result i32)))
)
The import format is (import $module $name $type).
$module is the module name, $name is the name of the function or memory to import, and $type contains the type definition information. For functions, it includes the function's signature information, and for memory, it defines the min and max information of the memory.
The binary structure looks like List 13.
List 13
; section "Type" (1)
0000008: 01 ; section code
0000009: 07 ; section size
000000a: 01 ; num types
; func type 0
000000b: 60 ; func
000000c: 02 ; num params
000000d: 7f ; i32
000000e: 7f ; i32
000000f: 01 ; num results
0000010: 7f ; i32
; section "Import" (2)
0000011: 02 ; section code
0000012: 0d ; section size
0000013: 01 ; num imports
; import header 0
0000014: 05 ; string length
0000015: 6164 6465 72 ; import module name (adder)
000001a: 03 ; string length
000001b: 6164 64 ; import field name (add)
000001e: 00 ; import kind
000001f: 00 ; import signature index
string length represents the length of the byte sequence of the characters, import module name represents the byte sequence of the actual module name, and import field name represents the byte sequence of the function or memory name to import.
import kind indicates the type of import, where 0 is used for functions.
import signature index points to the index of the function's signature information, referring to func type 0 in the Type Section.
Summary
In this chapter, we explained the sections targeted for implementation. If you are not familiar with handling binaries, it may seem challenging, but we recommend revisiting this chapter repeatedly until you become comfortable with it.
In the next chapter, we will proceed with implementing the process of decoding a Wasm binary.
How to implement binary decoding
In this chapter, we will use a parser combinator called nom to decode a Wasm binary that only contains a preamble, explaining the basic implementation of binary decoding.
The Rust version used in this book is as follows.
$ rustc --version
rustc 1.77.2 (25ef9e3d8 2024-04-09)
Also, the implementation of the Wasm Runtime created for this book is located in the following repository, so if there are any confusing parts, please refer directly to the code.
https://github.com/skanehira/tiny-wasm-runtime
Preparation
Let's create a Rust project right away and introduce the necessary crates.
$ cargo new tiny-wasm-runtime --name tinywasm
After creating the project, add the following to Cargo.toml.
[dependencies]
anyhow = "1.0.71" # Crate for easy error handling
nom = "7.1.3" # Parser combinator
nom-leb128 = "0.2.0" # For decoding LEB128 variable length code compressed numbers Crate
num-derive = "0.4.0" # Crate that makes converting numeric types convenient
num-traits = "0.2.15" # Crate that makes converting numeric types convenient
[dev-dependencies]
wat = "=1.0.67" # Crate for compiling Wasm binaries from WAT
pretty_assertions = "1.4.0" # Crate that makes it easier to see differences during testing
Decoding the Preamble
As explained in the chapter on the structure of Wasm binary, the preamble is structured as follows:
It consists of a total of 8 bytes, where the first 4 bytes are \0asm and the remaining 4 bytes are version information.
\0asm
┌───┴───┐
0000000: 0061 736d ; WASM_BINARY_MAGIC
~~~~~~~ ~~ ~~~~~~~~~~~~~~~~~~~~
│ │ │
│ │ └ Comment
│ └ Hexadecimal notation, 2 digits = 1 byte
└ Offset of address
0000004: 0100 0000 ; WASM_BINARY_VERSION
Representing this in a Rust struct would look like the following.
#![allow(unused)] fn main() { pub struct Module { pub magic: String, pub version: u32, } }
It's good to start with a small implementation, so let's start by implementing the decoding process of the preamble.
First, create the following files under the src directory.
src/binary.rssrc/lib.rssrc/binary/module.rs
For each file, write the following.
src/binary/module.rs
#![allow(unused)] fn main() { #[derive(Debug, PartialEq, Eq)] pub struct Module { pub magic: String, pub version: u32, } }
src/binary.rs
#![allow(unused)] fn main() { pub mod module; }
src/lib.rs
#![allow(unused)] fn main() { pub mod binary; }
Next, proceed with implementing the tests. In the tests, compile WAT code into Wasm binary and verify that the decoded result matches the expected data structure.
src/binary/module.rs
@@ -3,3 +3,17 @@ pub struct Module {
pub magic: String,
pub version: u32,
}
+
+#[cfg(test)]
+mod tests {
+ use crate::binary::module::Module;
+ use anyhow::Result;
+
+ #[test]
+ fn decode_simplest_module() -> Result<()> {
+ // Generate wasm binary with only preamble present
+ let wasm = wat::parse_str("(module)")?;
+ // Decode binary and generate Module structure
+ let module = Module::new(&wasm)?;
+ // Compare whether the generated Module structure is as expected
+ assert_eq!(module, Module::default());
+ Ok(())
+ }
+}
As shown in the code above, to pass the tests, you need to implement Moduele::new() and Module::default().
Since the magic number and version are constant, implementing the Default trait can reduce the amount of code written during testing.
First, implement Default().
src/binary/module.rs
pub version: u32,
}
+impl Default for Module {
+ fn default() -> Self {
+ Self {
+ magic: "\0asm".to_string(),
+ version: 1,
+ }
+ }
+}
+
#[cfg(test)]
mod tests {
use crate::binary::module::Module;
Next, proceed with the implementation of the decoding process.
src/binary/module.rs
+use nom::{IResult, number::complete::le_u32, bytes::complete::tag};
+
#[derive(Debug, PartialEq, Eq)]
pub struct Module {
pub magic: String,
@@ -13,6 +15,25 @@ impl Default for Module {
}
}
+impl Module {
+ pub fn new(input: &[u8]) -> anyhow::Result<Module> {
+ let (_, module) =
+ Module::decode(input).map_err(|e| anyhow::anyhow!("failed to parse wasm: {}", e))?;
+ Ok(module)
+ }
+
+ fn decode(input: &[u8]) -> IResult<&[u8], Module> {
+ let (input, _) = tag(b"\0asm")(input)?;
+ let (input, version) = le_u32(input)?;
+
+ let module = Module {
+ magic: "\0asm".into(),
+ version,
+ };
+ Ok((input, module))
+ }
+}
+
#[cfg(test)]
mod tests {
use crate::binary::module::Module;
With this, the decoding process of the preamble has been implemented, so if the tests pass, it's okay.
$ cargo test decode_simplest_module
Finished test [unoptimized + debuginfo] target(s) in 0.05s
Running unittests src/lib.rs (target/debug/deps/tinywasm-010073c10c93afeb)
running 1 test
test binary::module::tests::decode_simplest_module ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/tinywasm-9670d80381f93079)
Explanation of the Decoding Process
For those who are not familiar with using nom, the code above may not be easy to understand, so let's explain it.
If you already understand, feel free to skip this explanation.
First, nom is designed to take a byte sequence as input and return a tuple of the read byte sequence and the remaining byte sequence.
For example, when you pass input to le_u32(), you get the result (remaining byte sequence, read byte sequence).
#![allow(unused)] fn main() { let (input, version) = le_u32(input)?; }
le_u32() is one of the parsers provided by nom, which reads a 4-byte value in little-endian1 and returns the result converted to u32.
So, if you want to obtain a u32 numeric value from a byte sequence, you can use this function.
Additionally, nom also provides a parser called tag().
This parser returns an error if the input does not match the byte sequence passed to tag().
Think of it as being able to handle input validation and reading at the same time.
When looking at the above code, it can be understood that b"\0asm" is passed to tag() to read the input and retrieve only the remaining input.
#![allow(unused)] fn main() { let (input, _) = tag(b"\0asm")(input)?; }
By the way, if the passed value does not match the input, the following error will occur.
Error: failed to parse wasm: Parsing Error: Error { input: [0, 97, 115, 109, 1, 0, 0, 0], code: Tag }
In summary, the processing of the decode() function is as follows:
- Read 4 bytes from the beginning of the binary, if it matches
\0asm, receive the remaining input - Read another 4 bytes from the remaining input, convert it to a
u32value, and receive the input
Summary
In this chapter, we actually implemented the decoding of the preamble, explained the basic usage of nom, and the flow of decoding process.
Binary decoding basically involves parsing a byte sequence according to a format and converting it to the specified data type repeatedly, so the process itself is very simple.
It may be difficult at first, but with practice, you will get used to it, so take your time and don't rush. By the way, the author also had a hard time at first, but gradually got used to it by writing more, so please rest assured.
In the Wasm spec, binaries are encoded in little-endian.
Implementation section decoding
In the previous chapter, we explained the basic implementation methods for decoding. In this chapter, we will implement decoding functions.
To start, we will implement the smallest function that does nothing so that it can be decoded as follows:
(module
(func)
)
Compiling the above WAT to a Wasm binary results in the following binary structure:
0000000: 0061 736d ; WASM_BINARY_MAGIC
0000004: 0100 0000 ; WASM_BINARY_VERSION
; section "Type" (1)
0000008: 01 ; section code
0000009: 04 ; section size
000000a: 01 ; num types
; func type 0
000000b: 60 ; func
000000c: 00 ; num params
000000d: 00 ; num results
; section "Function" (3)
000000e: 03 ; section code
000000f: 02 ; section size
0000010: 01 ; num functions
0000011: 00 ; function 0 signature index
; section "Code" (10)
0000012: 0a ; section code
0000013: 04 ; section size
0000014: 01 ; num functions
; function body 0
0000015: 02 ; func body size
0000016: 00 ; local decl count
0000017: 0b ; end
Decoding Sections
To implement the decoding of functions, it is necessary to implement the decoding process for the following sections.
| Section | Description |
|---|---|
Type Section | Information about function signatures |
Code Section | Information such as instructions for each function |
Function Section | Reference information to function signatures |
The format of each section is as described in the chapter on the structure of Wasm binaries, so we will explain the implementation while referring to that.
Decoding Section Headers
Each section has a section header that always includes section code and section size. Therefore, first create the src/binary/section.rs file and define an Enum for section code.
src/binary/section.rs
#![allow(unused)] fn main() { use num_derive::FromPrimitive; #[derive(Debug, PartialEq, Eq, FromPrimitive)] pub enum SectionCode { Type = 0x01, Import = 0x02, Function = 0x03, Memory = 0x05, Export = 0x07, Code = 0x0a, Data = 0x0b, } }
src/binary.rs
pub mod module;
+pub mod section;
By looking at this SectionCode, we will proceed with the decoding process for each section.
#![allow(unused)] fn main() { match code { SectionCode::Type => { ... } SectionCode::Function => { ... } ... } }
Next, we will implement the function decode_section_header() to decode the section headers. This function simply retrieves section code and section size from the input, but there are some new functions, so we will explain them.
src/binary/module.rs
-use nom::{IResult, number::complete::le_u32, bytes::complete::tag};
+use super::section::SectionCode;
+use nom::{
+ bytes::complete::tag,
+ number::complete::{le_u32, le_u8},
+ sequence::pair,
+ IResult,
+};
+use nom_leb128::leb128_u32;
+use num_traits::FromPrimitive as _;
#[derive(Debug, PartialEq, Eq)]
pub struct Module {
@@ -34,6 +42,17 @@ impl Module {
}
}
+fn decode_section_header(input: &[u8]) -> IResult<&[u8], (SectionCode, u32)> {
+ let (input, (code, size)) = pair(le_u8, leb128_u32)(input)?; // 1
+ Ok((
+ input,
+ (
+ SectionCode::from_u8(code).expect("unexpected section code"), // 2
+ size,
+ ),
+ ))
+}
+
#[cfg(test)]
mod tests {
use crate::binary::module::Module;
1 pair() returns a new parser based on two parsers. The reason for using pair() is that the formats of section code and section size are fixed, so by parsing each of them together, we can process them in a single function call.
If pair() is not used, the implementation would look like this:
#![allow(unused)] fn main() { let (input, code) = le_u8(input); let (input, size) = leb128_u32(input); }
section code is fixed at 1 byte, so le_u8() is used.
section size is an u32 encoded with LEB1281, so when reading the value, leb128_u32() is needed.
Note that in the Wasm spec, all numbers are required to be encoded with LEB128. The author once spent several hours trying to pass tests without knowing this.
2 SectionCode::from_u8() is a function implemented with the num_derive::FromPrimitive macro. It is used to convert the read 1-byte number to a SectionCode. Without using this, a manual solution like the following would be necessary:
#![allow(unused)] fn main() { impl From<u8> for SectionCode { fn from(code: u8) -> Self { match code { 0x00 => Self::Custom, 0x01 => Self::Type, ... } } } }
Now that the implementation of decoding the section headers is done, we will proceed to implement the framework for decoding.
src/binary/module.rs
use super::section::SectionCode;
use nom::{
- bytes::complete::tag,
+ bytes::complete::{tag, take},
number::complete::{le_u32, le_u8},
sequence::pair,
IResult,
@@ -38,6 +38,29 @@ impl Module {
magic: "\0asm".into(),
version,
};
+
+ let mut remaining = input;
+
+ while !remaining.is_empty() { // 1
+ match decode_section_header(remaining) { // 2
+ Ok((input, (code, size))) => {
+ let (rest, section_contents) = take(size)(input)?; // 3
+
+ match code {
+ _ => todo!(), // 4
+ };
+
+ remaining = rest; // 5
+ }
+ Err(err) => return Err(err),
+ }
+ }
Ok((input, module))
}
}
In the above implementation, the following steps are performed:
- Repeat steps ② to ⑤ until the input
remainingis empty. - Decode the section header to obtain the section code, size, and remaining input.
- Retrieve a byte sequence of the section size from the remaining input.
take()is a function that reads a specified amount of input.- The read byte sequence is
section_contents, and the remaining isrest.
- Describe the decoding process for various sections.
- Reassign
remainingtorestto use it in the next loop.
The task is simple, but it may be difficult to understand at first, so let's consider processing steps 2 to 5 above based on the binary structure.
First, when extracting the binary structure parts of the Type Section and Function Section, it looks like this:
; section "Type" (1)
0000008: 01 ; section code
0000009: 04 ; section size
000000a: 01 ; num types
; func type 0
000000b: 60 ; func
000000c: 00 ; num params
000000d: 00 ; num results
; section "Function" (3)
000000e: 03 ; section code
000000f: 02 ; section size
0000010: 01 ; num functions
0000011: 00 ; function 0 signature index
...
At step 1, remaining looks like this:
| remaining |
|---|
| [0x01, 0x04, 0x01, 0x60, 0x0, 0x0, 0x03, 0x02, 0x01, 0x00, ...] |
After step 2, input and others look like this:
| section code | section size | input |
|---|---|---|
| 0x01 | 0x04 | [0x01, 0x60, 0x0, 0x0, 0x03, 0x02, 0x01, 0x00, ...] |
After step 3, rest and section_contents look like this:
| section_contents | rest |
|---|---|
| [0x01, 0x60, 0x0, 0x0] | [0x03, 0x02, 0x01, 0x00, ...] |
In step 4, further decoding is done on section_contents.
In step 5, the value of rest is assigned to remaining, making remaining the input for the next section at this point.
| remaining |
|---|
| [0x03, 0x02, 0x01, 0x00, ...] |
In this way, input is consumed repeatedly to decode each section. Once you understand it, it's simple, but until then, it's good to reread the explanation in this section repeatedly or try writing it yourself.
Decoding the Type Section
Now that the framework is set up, let's proceed to implement the decoding process for the Type Section.
The Type Section is a section that contains function signature information, where a signature consists of combinations of arguments and return values.
The binary structure is as follows:
; section "Type" (1)
0000008: 01 ; section code
0000009: 04 ; section size
000000a: 01 ; num types
; func type 0
000000b: 60 ; func
000000c: 00 ; num params
000000d: 00 ; num results
First, create the src/binary/types.rs file and define the structure of the signature.
src/binary/types.rs
#![allow(unused)] fn main() { #[derive(Debug, Default, Clone, PartialEq, Eq)] pub struct FuncType { pub params: Vec<ValueType>, pub results: Vec<ValueType>, } #[derive(Debug, Clone, PartialEq, Eq)] pub enum ValueType { I32, // 0x7F I64, // 0x7E } impl From<u8> for ValueType { fn from(value: u8) -> Self { match value { 0x7F => Self::I32, 0x7E => Self::I64, _ => panic!("invalid value type: {:X}", value), } } } }
pub mod module;
pub mod section;
+pub mod types;
ValueType represents the type of arguments.
In this case, since the defined function has no arguments, there is no type information in the binary structure, but according to the specification, 0x7F represents i32 and 0x7E represents i64.
In the Wasm Spec, 4 values are defined: i32, i64, f32, f64, but for this case, only i32 and i64 are needed, so we will implement only those two in ValueType.
Next, add the type_section field to the Module struct and start implementing todo!().
src/binary/module.rs
-use super::section::SectionCode;
+use super::{section::SectionCode, types::FuncType};
use nom::{
bytes::complete::{tag, take},
number::complete::{le_u32, le_u8},
@@ -12,6 +12,7 @@ use num_traits::FromPrimitive as _;
pub struct Module {
pub magic: String,
pub version: u32,
+ pub type_section: Option<Vec<FuncType>>,
}
impl Default for Module {
@@ -19,6 +20,7 @@ impl Default for Module {
Self {
magic: "\0asm".to_string(),
version: 1,
+ type_section: None,
}
}
}
@@ -34,9 +36,10 @@ impl Module {
let (input, _) = tag(b"\0asm")(input)?;
let (input, version) = le_u32(input)?;
- let module = Module {
+ let mut module = Module {
magic: "\0asm".into(),
version,
+ ..Default::default()
};
let mut remaining = input;
@@ -47,6 +50,10 @@ impl Module {
let (rest, section_contents) = take(size)(input)?;
match code {
+ SectionCode::Type => {
+ let (_, types) = decode_type_section(section_contents)?;
+ module.type_section = Some(types);
+ }
_ => todo!(),
};
decode_type_section() is the function that actually decodes the Type Section, but it becomes a bit complex, so for now, let's make it return fixed data.
We will implement argument and return value decoding along with the next chapter.
src/binary/module.rs
@@ -77,6 +77,14 @@ fn decode_section_header(input: &[u8]) -> IResult<&[u8], (SectionCode, u32)> {
))
}
+fn decode_type_section(_input: &[u8]) -> IResult<&[u8], Vec<FuncType>> {
+ let func_types = vec![FuncType::default()];
+
+ // TODO: Decoding arguments and return values
+
+ Ok((&[], func_types))
+}
+
#[cfg(test)]
mod tests {
use crate::binary::module::Module;
Decoding the Function Section
The Function Section is an area in the chapter on the structure of Wasm binaries that links to the signature information of functions (the Type Section).
The binary structure is as follows:
; section "Function" (3)
000000e: 03 ; section code
000000f: 02 ; section size
0000010: 01 ; num functions
0000011: 00 ; function 0 signature index
To decode this, first add the function_section to the Module.
src/binary/module.rs
@@ -13,6 +13,7 @@ pub struct Module {
pub magic: String,
pub version: u32,
pub type_section: Option<Vec<FuncType>>,
+ pub function_section: Option<Vec<u32>>,
}
impl Default for Module {
@@ -21,6 +22,7 @@ impl Default for Module {
magic: "\0asm".to_string(),
version: 1,
type_section: None,
+ function_section: None,
}
}
}
@@ -54,6 +56,10 @@ impl Module {
let (_, types) = decode_type_section(section_contents)?;
module.type_section = Some(types);
}
+ SectionCode::Function => {
+ let (_, func_idx_list) = decode_function_section(section_contents)?;
+ module.function_section = Some(func_idx_list);
+ }
_ => todo!(),
};
The Function Section simply holds index information to link the Type Section and Code Section, so in Rust, it is represented as Vec<u32>.
Next, implement decode_function_section() as follows.
At the point where decode_type_section() is called, the input looks like this:
num functions represents the number of functions, and we read the index values this many times.
0000010: 01 ; num functions
0000011: 00 ; function 0 signature index
The implementation will be as follows:
src/binary/module.rs
@@ -91,6 +91,19 @@ fn decode_type_section(_input: &[u8]) -> IResult<&[u8], Vec<FuncType>> {
Ok((&[], func_types))
}
+fn decode_function_section(input: &[u8]) -> IResult<&[u8], Vec<u32>> {
+ let mut func_idx_list = vec![];
+ let (mut input, count) = leb128_u32(input)?; // 1
+
+ for _ in 0..count { // 2
+ let (rest, idx) = leb128_u32(input)?;
+ func_idx_list.push(idx);
+ input = rest;
+ }
+
+ Ok((&[], func_idx_list))
+}
+
#[cfg(test)]
mod tests {
use crate::binary::module::Module;
Here, 1 reads num functions, and 2 reads the index values that many times.
Decoding the Code Section
The Code Section is the area where function information is stored.
Function information consists of two parts:
- Number and type information of local variables
- Instruction sequence
In Rust, this is represented as follows:
#![allow(unused)] fn main() { // function definition pub struct Function { pub locals: Vec<FunctionLocal>, pub code: Vec<Instruction>, } // Define the number of local variables and type information pub struct FunctionLocal { pub type_count: u32, // Number of local variables pub value_type: ValueType, // Variable type information } // 命令の定義 pub enum Instruction { LocalGet(u32), End, ... } }
The binary structure is as follows:
For a function that does nothing, there are no local variables, and only one end instruction.
The end instruction signifies the end of a function, and even for a function that does nothing, there must always be one end instruction.
; section "Code" (10)
0000012: 0a ; section code
0000013: 04 ; section size
0000014: 01 ; num functions
; function body 0
0000015: 02 ; func body size
0000016: 00 ; local decl count
0000017: 0b ; end
First, create the src/binary/instruction.rs file and define the instructions there.
src/binary/instruction.rs
#![allow(unused)] fn main() { #[derive(Debug, Clone, PartialEq, Eq)] pub enum Instruction { End, } }
src/binary.rs
+pub mod instruction;
pub mod module;
pub mod section;
pub mod types;
Next, define FunctionLocal to represent information about local variables.
src/binary/types.rs
@@ -19,3 +19,9 @@ impl From<u8> for ValueType {
}
}
}
+
+#[derive(Debug, Clone, PartialEq, Eq)]
+pub struct FunctionLocal {
+ pub type_count: u32,
+ pub value_type: ValueType,
+}
Continuing, define Function to represent a function.
src/binary/section.rs
+use super::{instruction::Instruction, types::FunctionLocal};
use num_derive::FromPrimitive;
#[derive(Debug, PartialEq, Eq, FromPrimitive)]
@@ -15,3 +16,9 @@ pub enum SectionCode {
Code = 0x0a,
Data = 0x0b,
}
+
+#[derive(Default, Debug, Clone, PartialEq, Eq)]
+pub struct Function {
+ pub locals: Vec<FunctionLocal>,
+ pub code: Vec<Instruction>,
+}
We would like to implement the decoding process next, but it becomes a bit complex, so for now, let's return a fixed data structure that passes the tests. We will implement the decoding process in the next chapter.
src/binary/module.rs
-use super::{section::SectionCode, types::FuncType};
+use super::{
+ instruction::Instruction,
+ section::{Function, SectionCode},
+ types::FuncType,
+};
use nom::{
bytes::complete::{tag, take},
number::complete::{le_u32, le_u8},
@@ -14,6 +18,7 @@ pub struct Module {
pub version: u32,
pub type_section: Option<Vec<FuncType>>,
pub function_section: Option<Vec<u32>>,
+ pub code_section: Option<Vec<Function>>,
}
impl Default for Module {
@@ -23,6 +28,7 @@ impl Default for Module {
version: 1,
type_section: None,
function_section: None,
+ code_section: None,
}
}
}
@@ -60,6 +66,10 @@ impl Module {
let (_, func_idx_list) = decode_function_section(section_contents)?;
module.function_section = Some(func_idx_list);
}
+ SectionCode::Code => {
+ let (_, funcs) = decode_code_section(section_contents)?;
+ module.code_section = Some(funcs);
+ }
_ => todo!(),
};
@@ -104,6 +114,16 @@ fn decode_function_section(input: &[u8]) -> IResult<&[u8], Vec<u32>> {
Ok((&[], func_idx_list))
}
+fn decode_code_section(_input: &[u8]) -> IResult<&[u8], Vec<Function>> {
+ // TODO: Decoding local variables and instructions
+ let functions = vec![Function {
+ locals: vec![],
+ code: vec![Instruction::End],
+ }];
+
+ Ok((&[], functions))
+}
+
#[cfg(test)]
mod tests {
use crate::binary::module::Module;
Finally, confirm that the tests pass. Although adjusting the implementation to pass the tests may seem trivial, it is fine for now as we will implement the decoding process properly in the next chapter.
src/binary/module.rs
@@ -126,7 +126,9 @@ fn decode_code_section(_input: &[u8]) -> IResult<&[u8], Vec<Function>> {
#[cfg(test)]
mod tests {
- use crate::binary::module::Module;
+ use crate::binary::{
+ instruction::Instruction, module::Module, section::Function, types::FuncType,
+ };
use anyhow::Result;
#[test]
@@ -136,4 +138,23 @@ mod tests {
assert_eq!(module, Module::default());
Ok(())
}
+
+ #[test]
+ fn decode_simplest_func() -> Result<()> {
+ let wasm = wat::parse_str("(module (func))")?;
+ let module = Module::new(&wasm)?;
+ assert_eq!(
+ module,
+ Module {
+ type_section: Some(vec![FuncType::default()]),
+ function_section: Some(vec![0]),
+ code_section: Some(vec![Function {
+ locals: vec![],
+ code: vec![Instruction::End],
+ }]),
+ ..Default::default()
+ }
+ );
+ Ok(())
+ }
}
Running the tests confirms that they pass.
running 2 tests
test binary::module::tests::decode_simplest_module ... ok
test binary::module::tests::decode_simplest_func ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Summary
While there are some TODOs remaining, this chapter explained the implementation of function decoding. You should now have a good understanding of the overall process, and in the next chapter, we will explain the implementation of decoding function arguments and return values, along with addressing the remaining TODOs.
A variable-length code compression method for storing numbers of arbitrary size in a small number of bytes.
Implementation instruction decoding
In the previous chapter, we implemented the decoding of the smallest function that does nothing, but left the following TODOs:
- Decode arguments and return values of the
Type Section. - Decode local variables and instructions of the
Code Section.
In this chapter, we will proceed with the implementation of these processes.
Decoding Function Arguments
We will implement the decoding of arguments, so define a function with arguments as follows:
(module
(func (param i32 i64)
)
)
The Type Section looks like this:
; section "Type" (1)
0000008: 01 ; section code
0000009: 06 ; section size
000000a: 01 ; num types
; func type 0
000000b: 60 ; func
000000c: 02 ; num params
000000d: 7f ; i32
000000e: 7e ; i64
000000f: 00 ; num results
Decode this following these steps:
- Read the number of function signatures,
num types- Repeat steps 2 to 6 this number of times
- Discard the value of
func- Represents the type of function signature, fixed as
0x60in theWasm spec - Not used in this document
- Represents the type of function signature, fixed as
- Read the number of arguments,
num params - Decode the type information of arguments this number of times
- Convert to
ValueTypefor0x7Fasi32and0x7Easi64
- Convert to
- Read the number of return values,
num results - Decode the type information of return values this number of times
- Convert to
ValueTypefor0x7Fasi32and0x7Easi64
- Convert to
The implementation of the above steps is as follows. The numbers in the comments correspond to the steps mentioned above.
/src/binary/module.rs
use super::{
instruction::Instruction,
section::{Function, SectionCode},
- types::FuncType,
+ types::{FuncType, ValueType},
};
use nom::{
bytes::complete::{tag, take},
+ multi::many0,
number::complete::{le_u32, le_u8},
sequence::pair,
IResult,
@@ -93,10 +94,33 @@ fn decode_section_header(input: &[u8]) -> IResult<&[u8], (SectionCode, u32)> {
))
}
-fn decode_type_section(_input: &[u8]) -> IResult<&[u8], Vec<FuncType>> {
- let func_types = vec![FuncType::default()];
+fn decode_value_type(input: &[u8]) -> IResult<&[u8], ValueType> {
+ let (input, value_type) = le_u8(input)?;
+ Ok((input, value_type.into()))
+}
+
+fn decode_type_section(input: &[u8]) -> IResult<&[u8], Vec<FuncType>> {
+ let mut func_types: Vec<FuncType> = vec![];
+
+ let (mut input, count) = leb128_u32(input)?; // 1
+
+ for _ in 0..count {
+ let (rest, _) = le_u8(input)?; // 2
+ let mut func = FuncType::default();
+
+ let (rest, size) = leb128_u32(rest)?; // 3
+ let (rest, types) = take(size)(rest)?;
+ let (_, types) = many0(decode_value_type)(types)?; // 4
+ func.params = types;
+
+ let (rest, size) = leb128_u32(rest)?; // 5
+ let (rest, types) = take(size)(rest)?;
+ let (_, types) = many0(decode_value_type)(types)?; // 6
+ func.results = types;
- // TODO: Decoding arguments and return values
+ func_types.push(func);
+ input = rest;
+ }
Ok((&[], func_types))
}
many0() is a function that parses input using the provided function until the input ends, returning the remaining input and parsing results as a Vec.
Here, we repeatedly apply the function decode_value_type() that reads u8 and converts it to ValueType.
By using many0(), we eliminate the need for a for loop for decoding, simplifying the implementation.
With the implementation completed, we will proceed to implement tests, focusing only on testing arguments at this point. To test return values, we need to implement instruction decoding separately.
/src/binary/module.rs
#[cfg(test)]
mod tests {
use crate::binary::{
- instruction::Instruction, module::Module, section::Function, types::FuncType,
+ instruction::Instruction,
+ module::Module,
+ section::Function,
+ types::{FuncType, ValueType},
};
use anyhow::Result;
@@ -181,4 +184,26 @@ mod tests {
);
Ok(())
}
+
+ #[test]
+ fn decode_func_param() -> Result<()> {
+ let wasm = wat::parse_str("(module (func (param i32 i64)))")?;
+ let module = Module::new(&wasm)?;
+ assert_eq!(
+ module,
+ Module {
+ type_section: Some(vec![FuncType {
+ params: vec![ValueType::I32, ValueType::I64],
+ results: vec![],
+ }]),
+ function_section: Some(vec![0]),
+ code_section: Some(vec![Function {
+ locals: vec![],
+ code: vec![Instruction::End],
+ }]),
+ ..Default::default()
+ }
+ );
+ Ok(())
+ }
}
If everything is correct, the tests should pass as follows.
running 3 tests
test binary::module::tests::decode_simplest_module ... ok
test binary::module::tests::decode_func_param ... ok
test binary::module::tests::decode_simplest_func ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Decoding Local Variables
Next, we will implement the decoding of local variables. The WAT code to be used is as follows:
(module
(func
(local i32)
(local i64 i64)
)
)
The binary structure of the Code Section is as follows:
; section "Code" (10)
0000012: 0a ; section code
0000013: 08 ; section size
0000014: 01 ; num functions
; function body 0
0000015: 06 ; func body size
0000016: 02 ; local decl count
0000017: 01 ; local type count
0000018: 7f ; i32
0000019: 02 ; local type count
000001a: 7e ; i64
000001b: 0b ; end
Decode this following these steps:
- Read the number of functions,
num functions- Repeat steps 2 to 5 this number of times
- Read
func body size - Extract the byte sequence obtained in step 2
- Used as input for decoding local variables and instructions
- Decode information of local variables using the byte sequence obtained in step 3
- Read the number of local variables,
local decl count - Repeat steps 4-3 to 4-4 this number of times
- Read the number of types,
local type count - Convert values to
ValueTypethis number of times
- Read the number of local variables,
Decode the remaining byte sequence into instructions.
The decoding of instructions will be implemented in the next section, but the flow is as described above. The implementation following these steps is as follows.
src/binary/module.rs
use super::{
instruction::Instruction,
section::{Function, SectionCode},
- types::{FuncType, ValueType},
+ types::{FuncType, FunctionLocal, ValueType},
};
use nom::{
bytes::complete::{tag, take},
@@ -138,16 +138,42 @@ fn decode_function_section(input: &[u8]) -> IResult<&[u8], Vec<u32>> {
Ok((&[], func_idx_list))
}
-fn decode_code_section(_input: &[u8]) -> IResult<&[u8], Vec<Function>> {
- // TODO: Decoding arguments and return values
- let functions = vec![Function {
- locals: vec![],
- code: vec![Instruction::End],
- }];
+fn decode_code_section(input: &[u8]) -> IResult<&[u8], Vec<Function>> {
+ let mut functions = vec![];
+ let (mut input, count) = leb128_u32(input)?; // 1
+
+ for _ in 0..count {
+ let (rest, size) = leb128_u32(input)?; // 2
+ let (rest, body) = take(size)(rest)?; // 3
+ let (_, body) = decode_function_body(body)?; // 4
+ functions.push(body);
+ input = rest;
+ }
Ok((&[], functions))
}
+fn decode_function_body(input: &[u8]) -> IResult<&[u8], Function> {
+ let mut body = Function::default();
+
+ let (mut input, count) = leb128_u32(input)?; // 4-1
+
+ for _ in 0..count { // 4-2
+ let (rest, type_count) = leb128_u32(input)?; // 4-3
+ let (rest, value_type) = le_u8(rest)?; // 4-4
+ body.locals.push(FunctionLocal {
+ type_count,
+ value_type: value_type.into(),
+ });
+ input = rest;
+ }
+
+ // TODO: Decoding instructions
+ body.code = vec![Instruction::End];
+
+ Ok((&[], body))
+}
+
#[cfg(test)]
mod tests {
use crate::binary::{
With the implementation completed, we will proceed to implement tests.
src/binary/module.rs
@@ -180,7 +180,7 @@ mod tests {
instruction::Instruction,
module::Module,
section::Function,
- types::{FuncType, ValueType},
+ types::{FuncType, ValueType, FunctionLocal},
};
use anyhow::Result;
@@ -232,4 +232,35 @@ mod tests {
);
Ok(())
}
+
+ #[test]
+ fn decode_func_local() -> Result<()> {
+ let wasm = wat::parse_file("src/fixtures/func_local.wat")?;
+ let module = Module::new(&wasm)?;
+ assert_eq!(
+ module,
+ Module {
+ type_section: Some(vec![FuncType::default()]),
+ function_section: Some(vec![0]),
+ code_section: Some(vec![Function {
+ locals: vec![
+ FunctionLocal {
+ type_count: 1,
+ value_type: ValueType::I32,
+ },
+ FunctionLocal {
+ type_count: 2,
+ value_type: ValueType::I64,
+ },
+ ],
+ code: vec![Instruction::End],
+ }]),
+ ..Default::default()
+ }
+ );
+ Ok(())
+ }
}
Prepare test data as well.
src/fixtures/func_local.wat
(module
(func
(local i32)
(local i64 i64)
)
)
If there are no issues, the test will pass.
running 4 tests
test binary::module::tests::decode_simplest_module ... ok
test binary::module::tests::decode_simplest_func ... ok
test binary::module::tests::decode_func_param ... ok
test binary::module::tests::decode_func_local ... ok
test result: ok. 4 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Instruction Decoding
In Wasm, instructions are basically composed of two parts: opcode and operand. The opcode is the identification number of the instruction, indicating what the instruction will do. The operand indicates the target of the instruction.
For example, the instruction i32.const performs the operation of pushing the operand value onto the stack.
In the case of (i32.const 1), it means pushing 1 onto the stack, and (i32.const 2) means pushing 2 onto the stack.
There are also instructions that do not have operands.
For example, i32.add pops two values from the stack, adds them, and pushes the result back onto the stack, but this instruction does not have an operand.
For each opcode, you can see what operation it performs in the Index of Instructions in the Wasm Spec. Although there are quite a number of instructions in the Index, only a few instructions will be implemented in this document.
Returning to the decoding discussion, in this section, we will implement decoding for the following WAT.
(module
(func (param i32 i32) (result i32)
(local.get 0)
(local.get 1)
i32.add
)
)
This is a function that takes two arguments, adds them, and returns the result.
local.get is an instruction that retrieves an argument and pushes it onto the stack, with the operand being the index of the argument.
For example, to retrieve the first argument, you would use 0, and for the second argument, you would use 1.
i32.add, as explained earlier, pops two values from the stack and adds them.
As a result, the sum of the two arguments is pushed onto the stack, and when the function returns to its caller, the return value can be obtained by popping the value from the stack.
The binary structure of the Code Section is as follows.
; section "Code" (10)
0000015: 0a ; section code
0000016: 09 ; section size
0000017: 01 ; num functions
; function body 0
0000018: 07 ; func body size
0000019: 00 ; local decl count
000001a: 20 ; local.get
000001b: 00 ; local index
000001c: 20 ; local.get
000001d: 01 ; local index
000001e: 6a ; i32.add
000001f: 0b ; end
Since the processing flow was explained in the previous section, only the steps for decoding instructions will be shown here.
- Decode the remaining byte sequence into instructions
- Read 1 byte and convert it to an opcode
- Depending on the type of opcode, read the operand
- For
local.get, read an additional 4 bytes, convert tou32, and combine with the opcode to convert to an instruction - For
i32.addandend, convert directly to an instruction
- For
Let's implement these steps.
First, create a file to define opcodes in src/binary/opcode.rs.
src/binary/opcode.rs
#![allow(unused)] fn main() { use num_derive::FromPrimitive; #[derive(Debug, FromPrimitive, PartialEq)] pub enum Opcode { End = 0x0B, LocalGet = 0x20, I32Add = 0x6A, } }
src/binary.rs
pub mod instruction;
pub mod module;
+pub mod opcode;
pub mod section;
pub mod types;
Next, add the definitions for instructions.
src/binary/instruction.rs
#[derive(Debug, Clone, PartialEq, Eq)]
pub enum Instruction {
End,
+ LocalGet(u32),
+ I32Add,
}
src/binary/module.rs
use super::{
instruction::Instruction,
section::{Function, SectionCode},
- types::{FuncType, FunctionLocal, ValueType},
+ types::{FuncType, FunctionLocal, ValueType}, opcode::Opcode,
};
use nom::{
bytes::complete::{tag, take},
@@ -168,12 +168,31 @@ fn decode_function_body(input: &[u8]) -> IResult<&[u8], Function> {
input = rest;
}
- // TODO: Decoding instructions
- body.code = vec![Instruction::End];
+ let mut remaining = input;
+
+ while !remaining.is_empty() { // 5
+ let (rest, inst) = decode_instructions(remaining)?;
+ body.code.push(inst);
+ remaining = rest;
+ }
Ok((&[], body))
}
+fn decode_instructions(input: &[u8]) -> IResult<&[u8], Instruction> {
+ let (input, byte) = le_u8(input)?;
+ let op = Opcode::from_u8(byte).unwrap_or_else(|| panic!("invalid opcode: {:X}", byte)); // 5-1
+ let (rest, inst) = match op { // 5-2
+ Opcode::LocalGet => { // 5-2-1
+ let (rest, idx) = leb128_u32(input)?;
+ (rest, Instruction::LocalGet(idx))
+ }
+ Opcode::I32Add => (input, Instruction::I32Add), // 5-2-2
+ Opcode::End => (input, Instruction::End), // 5-2-2
+ };
+ Ok((rest, inst))
+}
+
#[cfg(test)]
mod tests {
use crate::binary::{
Then, proceed with implementing the tests.
src/binary/module.rs
@@ -280,4 +280,31 @@ mod tests {
);
Ok(())
}
+
+ #[test]
+ fn decode_func_add() -> Result<()> {
+ let wasm = wat::parse_file("src/fixtures/func_add.wat")?;
+ let module = Module::new(&wasm)?;
+ assert_eq!(
+ module,
+ Module {
+ type_section: Some(vec![FuncType {
+ params: vec![ValueType::I32, ValueType::I32],
+ results: vec![ValueType::I32],
+ }]),
+ function_section: Some(vec![0]),
+ code_section: Some(vec![Function {
+ locals: vec![],
+ code: vec![
+ Instruction::LocalGet(0),
+ Instruction::LocalGet(1),
+ Instruction::I32Add,
+ Instruction::End
+ ],
+ }]),
+ ..Default::default()
+ }
+ );
+ Ok(())
+ }
}
Prepare test data as well.
/src/fixtures/func_add.wat
(module
(func (param i32 i32) (result i32)
(local.get 0)
(local.get 1)
i32.add
)
)
If there are no issues, the test will pass.
running 5 tests
test binary::module::tests::decode_simplest_module ... ok
test binary::module::tests::decode_simplest_func ... ok
test binary::module::tests::decode_func_param ... ok
test binary::module::tests::decode_func_add ... ok
test binary::module::tests::decode_func_local ... ok
test result: ok. 5 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Summary
In this chapter, we explained the implementation of function arguments, return values, local variables, and instruction decoding. Now that we can decode a basic functioning function, the next step is to explain the mechanism of function execution.
How function execution works
Executing a function means processing the instructions the function holds in a loop. In this chapter, we will explain how the Wasm Runtime processes functions.
Execution of Instructions
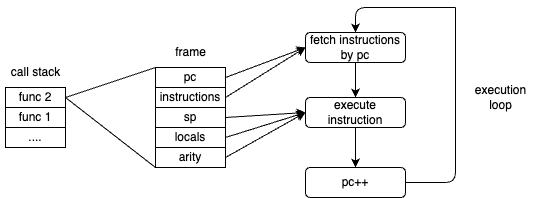
In Wasm Runtime, the execution of instructions can be broadly divided into the following steps:
- Fetching instructions using the program counter
- Processing the fetched instructions
- In this step, operations on the stack, local variables, etc., are also performed
- Incrementing the program counter
The program counter refers to the value that points to the address of the next instruction to be executed. In Wasm Runtime, instructions are represented as an array, so the program counter becomes the value of the array index.
Representing this in pseudocode would look like the following.
#![allow(unused)] fn main() { let instructions = vec![...]; // Instruction sequence let mut stack: Vec<i32> = vec![]; // Stack let mut locals: Vec<i32> = vec![]; // Local variables let mut pc: usize = 0; // Program counter loop { if let Some(instruction) = instructions.get(pc) else { break; }; match instruction { inst::LocalGet => { ... } inst::I32Add => { ... } ... } pc += 1; } }
Frame
A frame is a data structure that holds the necessary information for the execution of a function. Details about various items will be discussed later.
- Program counter (pc)
- Stack pointer (sp)
- Instruction sequence (instructions)
- Number of return values (arity)
- Arguments and local variables (locals)
When executing a function, a frame is created, and processing is done based on this information. In the Wasm Runtime implementation we are working on, frames are represented as follows.
#![allow(unused)] fn main() { #[derive(Default)] pub struct Frame { pub pc: isize, pub sp: usize, pub insts: Vec<Instruction>, pub arity: usize, pub locals: Vec<Value>, } }
Call Stack
The stack area that holds frames. When executing a function, a frame is created and pushed onto the call stack. Once the function execution is complete, it is popped from the call stack.
The relationship between the call stack, frames, and instruction execution can be illustrated as follows. The program counter and instruction sequence are used during instruction fetching, while the other information is used during instruction processing.
Stack Pointer
The call stack is stacked each time a function is executed, but there is always only one stack. Therefore, a common stack area is used between functions.
Since it is a common area, it is necessary to rewind the stack when a function execution is completed.
For example, if there are functions func1 and func2 that have processes to push values onto the stack.
When func1 calls func2 during its execution, and func2 finishes its execution with values pushed onto the stack, when returning to func1, the values pushed by func2 remain on the stack.
Therefore, it is necessary to rewind the stack to the state it was in when func1 called func2.
The stack pointer is the information needed to know how far to rewind the stack.
Arguments and Local Variables
Wasm functions can have arguments and local variables.
Since arguments are essentially local variables, they are saved in the locals of the frame.
When calling a function from another function, let's briefly explain how arguments are passed to the function.
Before executing a function, a frame is created. If there are functions that receive arguments, the arguments are poped from the stack and pushed into locals.
This allows the use of local variables when executing the function.
Number of Return Values
Wasm functions can return values.
When the function execution is completed and the stack is rewound, if there are return values, they are poped from the stack first before rewinding.
After that, the poped values are pushed back onto the stack.
This way, the result of the function execution is stacked, allowing the caller to continue processing.
Thinking of the function execution result being stacked is similar to pushing 1 onto the stack like i32.const 1, which might make it easier to visualize.
Summary
We have explained the mechanism of function execution in Wasm. There are aspects that may not be fully understood until implemented, so in the next chapter, we will proceed with the implementation to deepen the understanding.
Implementation function execution
In this chapter, we will implement a Runtime to execute the following WAT.
Once implemented, a Wasm Runtime capable of simple addition will be created.
(module
(func (param i32 i32) (result i32)
(local.get 0)
(local.get 1)
i32.add
)
)
The processing flow can be broadly divided as follows:
- Generate an
execution::Storeusingbinary::Module - Generate an
execution::Runtimeusing theexecution::Store - Execute a function using
execution::Runtime::call(...)
Implementation of Values
The Wasm Runtime we are implementing this time will handle the following two types of values, so let's implement them.
- i32
- i64
First, create the following files under src.
src/execution/value.rssrc/execution.rs
Implement them as follows.
src/execution/value.rs
#![allow(unused)] fn main() { #[derive(Debug, Clone, Copy, PartialEq, Eq)] pub enum Value { I32(i32), I64(i64), } impl From<i32> for Value { fn from(value: i32) -> Self { Value::I32(value) } } impl From<i64> for Value { fn from(value: i64) -> Self { Value::I64(value) } } impl std::ops::Add for Value { type Output = Self; fn add(self, rhs: Self) -> Self::Output { match (self, rhs) { (Value::I32(left), Value::I32(right)) => Value::I32(left + right), (Value::I64(left), Value::I64(right)) => Value::I64(left + right), _ => panic!("type mismatch"), } } } }
src/execution.rs
#![allow(unused)] fn main() { pub mod value; }
src/lib.rs
diff --git a/src/lib.rs b/src/lib.rs
index 96eab66..ec63376 100644
--- a/src/lib.rs
+++ b/src/lib.rs
@@ -1 +1,2 @@
pub mod binary;
+pub mod execution;
Since i32 and i64 are different types, they cannot be handled together on the stack.
Therefore, we provide an Enum called Value to handle them on the stack.
Additionally, we implement std::ops::Add to allow adding Value instances together.
Implementation of Store
Store is a struct that holds the state of the Wasm Runtime during execution.
As defined in the specification, it holds information such as memory, imports, and functions, which are used to process instructions.
If a Wasm binary is considered a class, then Store can be thought of as an instance of that class.
At this point, it is sufficient to have information about functions, so create the following file to implement Store.
src/execution/store.rs
#![allow(unused)] fn main() { use crate::binary::{ instruction::Instruction, types::{FuncType, ValueType}, }; #[derive(Clone)] pub struct Func { pub locals: Vec<ValueType>, pub body: Vec<Instruction>, } #[derive(Clone)] pub struct InternalFuncInst { pub func_type: FuncType, pub code: Func, } #[derive(Clone)] pub enum FuncInst { Internal(InternalFuncInst), } #[derive(Default)] pub struct Store { pub funcs: Vec<FuncInst>, } }
FuncInst represents the actual function processed by the Wasm Runtime.
There are imported functions and functions provided by the Wasm binary.
Since we are not using imported functions this time, we will first implement InternalFuncInst representing functions provided by the Wasm binary.
The fields of InternalFuncInst are as follows:
func_type: Information about the function's signature (arguments and return values)code: AFunctype that holds the function's local variable definitions and instruction sequences
Next, implement a function that takes a binary::Module and generates a Store.
src/execution/store.rs
diff --git a/src/execution/store.rs b/src/execution/store.rs
index e488383..5b4e467 100644
--- a/src/execution/store.rs
+++ b/src/execution/store.rs
@@ -1,7 +1,9 @@
use crate::binary::{
instruction::Instruction,
+ module::Module,
types::{FuncType, ValueType},
};
+use anyhow::{bail, Result};
#[derive(Clone)]
pub struct Func {
@@ -23,3 +25,44 @@ pub enum FuncInst {
pub struct Store {
pub funcs: Vec<FuncInst>,
}
+
+impl Store {
+ pub fn new(module: Module) -> Result<Self> {
+ let func_type_idxs = match module.function_section {
+ Some(ref idxs) => idxs.clone(),
+ _ => vec![],
+ };
+
+ let mut funcs = vec![];
+
+ if let Some(ref code_section) = module.code_section {
+ for (func_body, type_idx) in code_section.iter().zip(func_type_idxs.into_iter()) {
+ let Some(ref func_types) = module.type_section else {
+ bail!("not found type_section")
+ };
+
+ let Some(func_type) = func_types.get(type_idx as usize) else {
+ bail!("not found func type in type_section")
+ };
+
+ let mut locals = Vec::with_capacity(func_body.locals.len());
+ for local in func_body.locals.iter() {
+ for _ in 0..local.type_count {
+ locals.push(local.value_type.clone());
+ }
+ }
+
+ let func = FuncInst::Internal(InternalFuncInst {
+ func_type: func_type.clone(),
+ code: Func {
+ locals,
+ body: func_body.code.clone(),
+ },
+ });
+ funcs.push(func);
+ }
+ }
+
+ Ok(Self { funcs })
+ }
+}
Each section used in the implementation contains the following data:
| Section | Description |
|---|---|
Type Section | Information about function signatures |
Code Section | Information about instructions for each function |
Function Section | Reference information to function signatures |
To briefly explain what Store::new() is doing at this point, it is collecting the necessary information for executing functions scattered across each section.
It might be a bit confusing, so let's take a look at the func_add.wat and its binary::Module.
#![allow(unused)] fn main() { Module { type_section: Some(vec![FuncType { params: vec![ValueType::I32, ValueType::I32], results: vec![ValueType::I32], }]), function_section: Some(vec![0]), code_section: Some(vec![Function { locals: vec![], code: vec![ Instruction::LocalGet(0), Instruction::LocalGet(1), Instruction::I32Add, Instruction::End ], }]), ..Default::default() } }
To know what signature the function in code_section[0] has, you need to retrieve the value of function_section[0.
This value corresponds to the index in type_section, so type_section[0] directly provides the signature information for code_section[0.
For example, if the value of function_section[0] is 1, then type_section[1] contains the signature information for code_section[0.
Implementation of Runtime
Runtime is the Wasm Runtime itself, which is a structure that holds the following information:
Store- Stack
- Call stack
In the previous chapter, we explained about the stack and call stack, so now we will explain how to implement and use them.
First, add src/execution/runtime.rs to define Runtime and Frame.
#![allow(unused)] fn main() { use super::{store::Store, value::Value}; use crate::binary::{instruction::Instruction, module::Module}; use anyhow::Result; #[derive(Default)] pub struct Frame { pub pc: isize, // Program counter pub sp: usize, // Stack pointer pub insts: Vec<Instruction>, // Instructions pub arity: usize, // Number of return values pub locals: Vec<Value>, // Local variables } #[derive(Default)] pub struct Runtime { pub store: Store, pub stack: Vec<Value>, pub call_stack: Vec<Frame>, } impl Runtime { pub fn instantiate(wasm: impl AsRef<[u8]>) -> Result<Self> { let module = Module::new(wasm.as_ref())?; let store = Store::new(module)?; Ok(Self { store, ..Default::default() }) } } }
src/execution.rs
diff --git a/src/execution.rs b/src/execution.rs
index 1a50587..acbafa4 100644
--- a/src/execution.rs
+++ b/src/execution.rs
@@ -1,2 +1,3 @@
+pub mod runtime;
pub mod store;
pub mod value;
Runtime::instantiate(...) is a function that takes a Wasm binary and generates a Runtime.
Implementation of Instruction Processing
Next, implement Runtime::execute(...) to execute instructions.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index c45d764..9db8415 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -1,6 +1,6 @@
use super::{store::Store, value::Value};
use crate::binary::{instruction::Instruction, module::Module};
-use anyhow::Result;
+use anyhow::{bail, Result};
#[derive(Default)]
pub struct Frame {
@@ -27,4 +27,38 @@ impl Runtime {
..Default::default()
})
}
+
+ fn execute(&mut self) -> Result<()> {
+ loop {
+ let Some(frame) = self.call_stack.last_mut() else { // 1
+ break;
+ };
+
+ frame.pc += 1;
+
+ let Some(inst) = frame.insts.get(frame.pc as usize) else { // 2
+ break;
+ };
+
+ match inst { // 3
+ Instruction::I32Add => {
+ let (Some(right), Some(left)) = (self.stack.pop(), self.stack.pop()) else {
+ bail!("not found any value in the stack");
+ };
+ let result = left + right;
+ self.stack.push(result);
+ }
+ }
+ }
+ Ok(())
+ }
}
The execute(...) method loops until there are no more instructions pointed to by the program counter.
- Get the top frame from the call stack.
- Increment the program counter (pc) and get the next instruction from the frame.
- Process each instruction:
For an instruction like
i32.add, pop two values from the stack, add them, and push the result back onto the stack.
The process is almost the same as the pseudocode shown in the previous chapter.
Next, implement the local.get and end instructions.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 6d090e9..5bae7fb 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -41,6 +41,12 @@ impl Runtime {
};
match inst {
+ Instruction::LocalGet(idx) => {
+ let Some(value) = frame.locals.get(*idx as usize) else {
+ bail!("not found local");
+ };
+ self.stack.push(*value);
+ }
Instruction::I32Add => {
let (Some(right), Some(left)) = (self.stack.pop(), self.stack.pop()) else {
bail!("not found any value in the stack");
The local.get instruction retrieves the value of a local variable and pushes it onto the stack.
local.get has an operand that indicates which local variable's value to retrieve, using the index value in frame.locals.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 5bae7fb..ceaf3dc 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -41,6 +41,13 @@ impl Runtime {
};
match inst {
+ Instruction::End => {
+ let Some(frame) = self.call_stack.pop() else { // 1
+ bail!("not found frame");
+ };
+ let Frame { sp, arity, .. } = frame; // 2
+ stack_unwind(&mut self.stack, sp, arity)?; // 3
+ }
Instruction::LocalGet(idx) => {
let Some(value) = frame.locals.get(*idx as usize) else {
bail!("not found local");
@@ -59,3 +66,16 @@ impl Runtime {
Ok(())
}
}
+
+pub fn stack_unwind(stack: &mut Vec<Value>, sp: usize, arity: usize) -> Result<()> {
+ if arity > 0 { // 3-1
+ let Some(value) = stack.pop() else {
+ bail!("not found return value");
+ };
+ stack.drain(sp..);
+ stack.push(value); // 3-2
+ } else {
+ stack.drain(sp..); // 3-3
+ }
+ Ok(())
+}
The end instruction signifies the end of function execution and performs the following steps:
- Pop the frame from the call stack.
- Retrieve the stack pointer (sp) and arity (number of return values) from the frame information.
- Rewind the stack:
- If there are return values, pop one value from the stack and rewind the stack to sp.
- Push the popped value back onto the stack.
- If there are no return values, simply rewind the stack to sp.
With the base implementation of Runtime::execute(...) complete, the next step is to implement Runtime::invoke_internal(...) for pre and post-processing of instruction execution.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index ceaf3dc..3356b37 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -1,5 +1,8 @@
-use super::{store::Store, value::Value};
-use crate::binary::{instruction::Instruction, module::Module};
+use super::{
+ store::{InternalFuncInst, Store},
+ value::Value,
+};
+use crate::binary::{instruction::Instruction, module::Module, types::ValueType};
use anyhow::{bail, Result};
#[derive(Default)]
@@ -28,6 +31,43 @@ impl Runtime {
})
}
+ fn invoke_internal(&mut self, func: InternalFuncInst) -> Result<Option<Value>> {
+ let bottom = self.stack.len() - func.func_type.params.len(); // 1
+ let mut locals = self.stack.split_off(bottom); // 2
+
+ for local in func.code.locals.iter() { // 3
+ match local {
+ ValueType::I32 => locals.push(Value::I32(0)),
+ ValueType::I64 => locals.push(Value::I64(0)),
+ }
+ }
+
+ let arity = func.func_type.results.len(); // 4
+
+ let frame = Frame {
+ pc: -1,
+ sp: self.stack.len(),
+ insts: func.code.body.clone(),
+ arity,
+ locals,
+ };
+
+ self.call_stack.push(frame); // 5
+
+ if let Err(e) = self.execute() { // 6
+ self.cleanup();
+ bail!("failed to execute instructions: {}", e)
+ };
+
+ if arity > 0 { // 7
+ let Some(value) = self.stack.pop() else {
+ bail!("not found return value")
+ };
+ return Ok(Some(value));
+ }
+ Ok(None)
+ }
+
fn execute(&mut self) -> Result<()> {
loop {
let Some(frame) = self.call_stack.last_mut() else {
@@ -65,6 +105,11 @@ impl Runtime {
}
Ok(())
}
+
+ fn cleanup(&mut self) {
+ self.stack = vec![];
+ self.call_stack = vec![];
+ }
}
pub fn stack_unwind(stack: &mut Vec<Value>, sp: usize, arity: usize) -> Result<()> {
In Runtime::invoke_internal(...), the following steps are performed:
- Get the number of function arguments.
- Pop values from the stack for each argument.
- Initialize local variables.
- Get the number of function return values.
- Create a frame and push it onto
Runtime::call_stack. - Call
Runtime::execute()to execute the function. - If there are return values, pop them from the stack and return them; otherwise, return
None.
Next, implement Runtime::call(...) which calls Runtime::invoke_internal(...) and allows specifying the function to call and passing function arguments.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 3356b37..7cba836 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -1,5 +1,5 @@
use super::{
- store::{InternalFuncInst, Store},
+ store::{FuncInst, InternalFuncInst, Store},
value::Value,
};
use crate::binary::{instruction::Instruction, module::Module, types::ValueType};
@@ -31,6 +31,18 @@ impl Runtime {
})
}
+ pub fn call(&mut self, idx: usize, args: Vec<Value>) -> Result<Option<Value>> {
+ let Some(func_inst) = self.store.funcs.get(idx) else { // 1
+ bail!("not found func")
+ };
+ for arg in args { // 2
+ self.stack.push(arg);
+ }
+ match func_inst {
+ FuncInst::Internal(func) => self.invoke_internal(func.clone()), // 3
+ }
+ }
+
fn invoke_internal(&mut self, func: InternalFuncInst) -> Result<Option<Value>> {
let bottom = self.stack.len() - func.func_type.params.len();
let mut locals = self.stack.split_off(bottom);
In Runtime::call(...), the following steps are performed:
- Get the
InternalFuncInst(function entity) held byStoreusing the specified index. - Push arguments onto the stack.
- Pass the
InternalFuncInstobtained in step 1 toRuntime::invoke_internal(...)for execution and return the result.
With this, a Wasm Runtime capable of executing addition functions has been created. Finally, write tests to ensure it functions correctly.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 7cba836..7fa35d2 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -136,3 +136,24 @@ pub fn stack_unwind(stack: &mut Vec<Value>, sp: usize, arity: usize) -> Result<(
}
Ok(())
}
+
+#[cfg(test)]
+mod tests {
+ use super::Runtime;
+ use crate::execution::value::Value;
+ use anyhow::Result;
+
+ #[test]
+ fn execute_i32_add() -> Result<()> {
+ let wasm = wat::parse_file("src/fixtures/func_add.wat")?;
+ let mut runtime = Runtime::instantiate(wasm)?;
+ let tests = vec![(2, 3, 5), (10, 5, 15), (1, 1, 2)];
+
+ for (left, right, want) in tests {
+ let args = vec![Value::I32(left), Value::I32(right)];
+ let result = runtime.call(0, args)?;
+ assert_eq!(result, Some(Value::I32(want)));
+ }
+ Ok(())
+ }
+}
If there are no issues, the test should pass as follows.
running 6 tests
test binary::module::tests::decode_simplest_module ... ok
test binary::module::tests::decode_func_param ... ok
test binary::module::tests::decode_func_local ... ok
test binary::module::tests::decode_simplest_func ... ok
test binary::module::tests::decode_func_add ... ok
test execution::runtime::tests::execute_i32_add ... ok
Summary
In this chapter, we implemented a Runtime that can perform addition and confirmed that it works. Now that the template is ready, we will further expand in the next chapters and implement function calls.
Implementation function call
In this chapter, we will extend the implementation from the previous chapter to implement the following features.
- Execute only exported functions
- Call functions
Execute only exported functions
In the previous chapter, we specified the function to be executed by index.
#![allow(unused)] fn main() { let args = vec![Value::I32(left), Value::I32(right)]; let result = runtime.call(0, args)?; assert_eq!(result, Some(Value::I32(want))); }
It is very inconvenient because you cannot specify the function you want to execute without analyzing the binary structure.
Also, according to the Wasm spec, it is specified that only exported functions can be executed, but the current implementation does not meet this specification.
Therefore, in this section, we will enable executing functions by specifying the function name.
Implementation of decoding the Export Section
Modify func_add.wat as follows to export a function named add.
src/fixtures/func_add.wat
diff --git a/src/fixtures/func_add.wat b/src/fixtures/func_add.wat
index ce14757..99678c4 100644
--- a/src/fixtures/func_add.wat
+++ b/src/fixtures/func_add.wat
@@ -1,5 +1,5 @@
(module
- (func (param i32 i32) (result i32)
+ (func (export "add") (param i32 i32) (result i32)
(local.get 0)
(local.get 1)
i32.add
Since the decoding of the Export Section has not been implemented, the test currently fails, so let's implement it.
Regarding the binary structure, it has already been explained in the chapter Wasm Binary Structure, so please refer to it.
First, define the type representing exports.
src/binary/types.rs
diff --git a/src/binary/types.rs b/src/binary/types.rs
index 7707a97..191c34b 100644
--- a/src/binary/types.rs
+++ b/src/binary/types.rs
@@ -25,3 +25,14 @@ pub struct FunctionLocal {
pub type_count: u32,
pub value_type: ValueType,
}
+
+#[derive(Debug, Clone, PartialEq, Eq)]
+pub enum ExportDesc {
+ Func(u32),
+}
+
+#[derive(Debug, PartialEq, Eq)]
+pub struct Export {
+ pub name: String,
+ pub desc: ExportDesc,
+}
Export::name is the export name, which will be add in this case.
ExportDesc is a reference to the entity such as a function or memory, and for functions, it will be the index value of Store::funcs.
For example, in the case of ExportDesc::Func(0), the entity of the function named add will be Store::funcs[0].
In this book, we will not implement exporting memories, so we will only implement ExportDesc::Func.
Next, implement the decoding of the Export Section.
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index 5ea23a1..949aea9 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -2,7 +2,7 @@ use super::{
instruction::Instruction,
opcode::Opcode,
section::{Function, SectionCode},
- types::{FuncType, FunctionLocal, ValueType},
+ types::{Export, ExportDesc, FuncType, FunctionLocal, ValueType},
};
use nom::{
bytes::complete::{tag, take},
@@ -194,6 +194,27 @@ fn decode_instructions(input: &[u8]) -> IResult<&[u8], Instruction> {
Ok((rest, inst))
}
+fn decode_export_section(input: &[u8]) -> IResult<&[u8], Vec<Export>> {
+ let (mut input, count) = leb128_u32(input)?; // 1
+ let mut exports = vec![];
+
+ for _ in 0..count { // 9
+ let (rest, name_len) = leb128_u32(input)?; // 2
+ let (rest, name_bytes) = take(name_len)(rest)?; // 3
+ let name = String::from_utf8(name_bytes.to_vec()).expect("invalid utf-8 string"); // 4
+ let (rest, export_kind) = le_u8(rest)?; // 5
+ let (rest, idx) = leb128_u32(rest)?; // 6
+ let desc = match export_kind { // 7
+ 0x00 => ExportDesc::Func(idx),
+ _ => unimplemented!("unsupported export kind: {:X}", export_kind),
+ };
+ exports.push(Export { name, desc }); // 8
+ input = rest;
+ }
+
+ Ok((input, exports))
+}
+
#[cfg(test)]
mod tests {
use crate::binary::{
In decode_export_section(...), the following steps are performed:
- Obtain the number of exports In this case, there is only one exported function, so it will be 1.
- Obtain the length of the byte sequence for the export name
- Obtain the byte sequence for the length obtained in step 2
- Convert the byte sequence obtained in step 3 to a string
- Obtain the type of export (function, memory, etc.)
- Obtain a reference to the entity exported, such as a function
- If it is
0x00, the export type is a function, so generate anExport - Add the
Exportgenerated in step 7 to an array - Repeat steps 2 to 8 for the number of elements
With this, the decoding of the Export Section has been implemented. Next, add export_section to Module as follows.
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index d14704f..41c9a89 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -21,6 +21,7 @@ pub struct Module {
pub type_section: Option<Vec<FuncType>>,
pub function_section: Option<Vec<u32>>,
pub code_section: Option<Vec<Function>>,
+ pub export_section: Option<Vec<Export>>,
}
impl Default for Module {
@@ -31,6 +32,7 @@ impl Default for Module {
type_section: None,
function_section: None,
code_section: None,
+ export_section: None,
}
}
}
@@ -72,6 +74,10 @@ impl Module {
let (_, funcs) = decode_code_section(section_contents)?;
module.code_section = Some(funcs);
}
+ SectionCode::Export => {
+ let (_, exports) = decode_export_section(section_contents)?;
+ module.export_section = Some(exports);
+ }
_ => todo!(),
};
@@ -221,7 +227,7 @@ mod tests {
instruction::Instruction,
module::Module,
section::Function,
- types::{FuncType, FunctionLocal, ValueType},
+ types::{Export, ExportDesc, FuncType, FunctionLocal, ValueType},
};
use anyhow::Result;
Also, update the tests.
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index 41c9a89..9ba5afc 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -329,6 +329,10 @@ mod tests {
Instruction::End
],
}]),
+ export_section: Some(vec![Export {
+ name: "add".into(),
+ desc: ExportDesc::Func(0),
+ }]),
..Default::default()
}
);
Now the tests should pass.
running 6 tests
test binary::module::tests::decode_simplest_module ... ok
test binary::module::tests::decode_simplest_func ... ok
test binary::module::tests::decode_func_local ... ok
test binary::module::tests::decode_func_param ... ok
test execution::runtime::tests::execute_i32_add ... ok
test binary::module::tests::decode_func_add ... ok
Implementation of function execution
Now that the section decoding is done, let's implement the ability to execute functions by specifying the function name.
First, define ModuleInst that holds ExportInst (export information).
By making ModuleInst::exports a HashMap, it becomes easy to look up function export information from the function name.
src/execution/store.rs
diff --git a/src/execution/store.rs b/src/execution/store.rs
index 2cd9821..d103fa0 100644
--- a/src/execution/store.rs
+++ b/src/execution/store.rs
@@ -1,7 +1,9 @@
+use std::collections::HashMap;
+
use crate::binary::{
instruction::Instruction,
module::Module,
- types::{FuncType, ValueType},
+ types::{ExportDesc, FuncType, ValueType},
};
use anyhow::{bail, Result};
@@ -21,9 +23,20 @@ pub enum FuncInst {
Internal(InternalFuncInst),
}
+pub struct ExportInst {
+ pub name: String,
+ pub desc: ExportDesc,
+}
+
+#[derive(Default)]
+pub struct ModuleInst {
+ pub exports: HashMap<String, ExportInst>,
+}
+
#[derive(Default)]
pub struct Store {
pub funcs: Vec<FuncInst>,
+ pub module: ModuleInst,
}
impl Store {
Next, generate ModuleInst from Module::export_section.
src/execution/store.rs
diff --git a/src/execution/store.rs b/src/execution/store.rs
index d103fa0..3f6ecb2 100644
--- a/src/execution/store.rs
+++ b/src/execution/store.rs
@@ -76,6 +76,22 @@ impl Store {
}
}
- Ok(Self { funcs })
+ let mut exports = HashMap::default();
+ if let Some(ref sections) = module.export_section {
+ for export in sections {
+ let name = export.name.clone();
+ let export_inst = ExportInst {
+ name: name.clone(),
+ desc: export.desc.clone(),
+ };
+ exports.insert(name, export_inst);
+ }
+ };
+ let module_inst = ModuleInst { exports };
+
+ Ok(Self {
+ funcs,
+ module: module_inst,
+ })
}
}
Continuing, modify to receive the function name in Runtime::call(...) and update to retrieve the index from ModuleInst to the function.
Also, update the tests to pass the function name.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 4fe757a..1885646 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -2,8 +2,12 @@ use super::{
store::{FuncInst, InternalFuncInst, Store},
value::Value,
};
-use crate::binary::{instruction::Instruction, module::Module, types::ValueType};
-use anyhow::{bail, Result};
+use crate::binary::{
+ instruction::Instruction,
+ module::Module,
+ types::{ExportDesc, ValueType},
+};
+use anyhow::{anyhow, bail, Result};
#[derive(Default)]
pub struct Frame {
@@ -31,7 +35,17 @@ impl Runtime {
})
}
- pub fn call(&mut self, idx: usize, args: Vec<Value>) -> Result<Option<Value>> {
+ pub fn call(&mut self, name: impl Into<String>, args: Vec<Value>) -> Result<Option<Value>> {
+ let idx = match self
+ .store
+ .module
+ .exports
+ .get(&name.into())
+ .ok_or(anyhow!("not found export function"))?
+ .desc
+ {
+ ExportDesc::Func(idx) => idx as usize,
+ };
let Some(func_inst) = self.store.funcs.get(idx) else {
bail!("not found func")
};
@@ -151,7 +165,7 @@ mod tests {
for (left, right, want) in tests {
let args = vec![Value::I32(left), Value::I32(right)];
- let result = runtime.call(0, args)?;
+ let result = runtime.call("add", args)?;
assert_eq!(result, Some(Value::I32(want)));
}
Ok(())
With this change, the following test will pass.
running 6 tests
test binary::module::tests::decode_simplest_func ... ok
test binary::module::tests::decode_func_param ... ok
test binary::module::tests::decode_func_local ... ok
test binary::module::tests::decode_simplest_module ... ok
test binary::module::tests::decode_func_add ... ok
test execution::runtime::tests::execute_i32_add ... ok
Additionally, add a test for specifying a non-existent function to verify.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 1885646..acc48cf 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -170,4 +170,13 @@ mod tests {
}
Ok(())
}
+
+ #[test]
+ fn not_found_export_function() -> Result<()> {
+ let wasm = wat::parse_file("src/fixtures/func_add.wat")?;
+ let mut runtime = Runtime::instantiate(wasm)?;
+ let result = runtime.call("fooooo", vec![]);
+ assert!(result.is_err());
+ Ok(())
+ }
}
running 1 test
test execution::runtime::tests::not_found_export_function ... ok
Implementation of Function Calls
In Wasm, functions can call other functions. Of course, it is also possible for a function to call itself recursively.
In this section, we will implement the ability to make the following function calls. The call_doubler function takes one argument, passes it to the double function, and returns double the value.
(module
(func (export "call_doubler") (param i32) (result i32)
(local.get 0)
(call $double)
)
(func $double (param i32) (result i32)
(local.get 0)
(local.get 0)
i32.add
)
)
Implementation of call Instruction Decoding
First, implement the decoding of function call instructions.
src/binary/opcode.rs
diff --git a/src/binary/opcode.rs b/src/binary/opcode.rs
index 98c075e..5d0a2b7 100644
--- a/src/binary/opcode.rs
+++ b/src/binary/opcode.rs
@@ -5,4 +5,5 @@ pub enum Opcode {
End = 0x0B,
LocalGet = 0x20,
I32Add = 0x6A,
+ Call = 0x10,
}
src/binary/instruction.rs
diff --git a/src/binary/instruction.rs b/src/binary/instruction.rs
index 1307caa..c9c6584 100644
--- a/src/binary/instruction.rs
+++ b/src/binary/instruction.rs
@@ -3,4 +3,5 @@ pub enum Instruction {
End,
LocalGet(u32),
I32Add,
+ Call(u32),
}
The function call instruction has an operand that holds a reference (index) to the function, so decode that.
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index 9ba5afc..3a3316c 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -196,6 +196,10 @@ fn decode_instructions(input: &[u8]) -> IResult<&[u8], Instruction> {
}
Opcode::I32Add => (input, Instruction::I32Add),
Opcode::End => (input, Instruction::End),
+ Opcode::Call => {
+ let (rest, idx) = leb128_u32(input)?;
+ (rest, Instruction::Call(idx))
+ }
};
Ok((rest, inst))
}
Next, skip decoding the custom sections and add tests.
src/binary/section.rs
diff --git a/src/binary/section.rs b/src/binary/section.rs
index a9a11b3..44e9884 100644
--- a/src/binary/section.rs
+++ b/src/binary/section.rs
@@ -3,6 +3,7 @@ use num_derive::FromPrimitive;
#[derive(Debug, PartialEq, Eq, FromPrimitive)]
pub enum SectionCode {
+ Custom = 0x00,
Type = 0x01,
Import = 0x02,
Function = 0x03,
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index acc48cf..bc2a20b 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -127,6 +127,7 @@ impl Runtime {
let result = left + right;
self.stack.push(result);
}
+ _ => todo!(),
}
}
Ok(())
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index 3a3316c..5bf739d 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -62,6 +62,9 @@ impl Module {
let (rest, section_contents) = take(size)(input)?;
match code {
+ SectionCode::Custom => {
+ // skip
+ }
SectionCode::Type => {
let (_, types) = decode_type_section(section_contents)?;
module.type_section = Some(types);
@@ -342,4 +345,45 @@ mod tests {
);
Ok(())
}
+
+ #[test]
+ fn decode_func_call() -> Result<()> {
+ let wasm = wat::parse_file("src/fixtures/func_call.wat")?;
+ let module = Module::new(&wasm)?;
+ assert_eq!(
+ module,
+ Module {
+ type_section: Some(vec![FuncType {
+ params: vec![ValueType::I32],
+ results: vec![ValueType::I32],
+ },]),
+ function_section: Some(vec![0, 0]),
+ code_section: Some(vec![
+ Function {
+ locals: vec![],
+ code: vec![
+ Instruction::LocalGet(0),
+ Instruction::Call(1),
+ Instruction::End
+ ],
+ },
+ Function {
+ locals: vec![],
+ code: vec![
+ Instruction::LocalGet(0),
+ Instruction::LocalGet(0),
+ Instruction::I32Add,
+ Instruction::End
+ ],
+ }
+ ]),
+ export_section: Some(vec![Export {
+ name: "call_doubler".into(),
+ desc: ExportDesc::Func(0),
+ }]),
+ ..Default::default()
+ }
+ );
+ Ok(())
+ }
}
Custom sections refer to the metadata area where you can freely place any data. Although not specifically used in this book, when using the wat crate with WAT, it adds custom sections during compilation, so it is necessary to skip them.
If the implementation is correct, the following test will pass.
running 8 tests
test binary::module::tests::decode_simplest_module ... ok
test binary::module::tests::decode_simplest_func ... ok
test binary::module::tests::decode_func_param ... ok
test binary::module::tests::decode_func_local ... ok
test binary::module::tests::decode_func_add ... ok
test binary::module::tests::decode_func_call ... ok
test execution::runtime::tests::not_found_export_function ... ok
test execution::runtime::tests::execute_i32_add ... ok
Implementation of call Instruction Processing
Now that the decoding process is implemented, proceed to implement the instruction processing.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index bc2a20b..f65d61e 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -57,7 +57,7 @@ impl Runtime {
}
}
- fn invoke_internal(&mut self, func: InternalFuncInst) -> Result<Option<Value>> {
+ fn push_frame(&mut self, func: &InternalFuncInst) {
let bottom = self.stack.len() - func.func_type.params.len();
let mut locals = self.stack.split_off(bottom);
@@ -79,6 +79,12 @@ impl Runtime {
};
self.call_stack.push(frame);
+ }
+
+ fn invoke_internal(&mut self, func: InternalFuncInst) -> Result<Option<Value>> {
+ let arity = func.func_type.results.len();
+
+ self.push_frame(&func);
if let Err(e) = self.execute() {
self.cleanup();
@@ -127,7 +133,14 @@ impl Runtime {
let result = left + right;
self.stack.push(result);
}
- _ => todo!(),
+ Instruction::Call(idx) => {
+ let Some(func) = self.store.funcs.get(*idx as usize) else {
+ bail!("not found func");
+ };
+ match func {
+ FuncInst::Internal(func) => self.push_frame(&func.clone()),
+ }
+ }
}
}
Ok(())
The task for a function call instruction is simple: retrieve the InternalFuncInst specified by the index from the Store, create a frame, and push it onto the call stack.
Since the process of receiving InternalFuncInst and pushing a frame to the call stack is common, it is extracted as Runtime::push_frame(...) to be used in Runtime::invoke_internal(...) for the call instruction processing.
Finally, add tests to ensure the implementation is correct.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index f65d61e..509ec05 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -193,4 +193,18 @@ mod tests {
assert!(result.is_err());
Ok(())
}
+
+ #[test]
+ fn func_call() -> Result<()> {
+ let wasm = wat::parse_file("src/fixtures/func_call.wat")?;
+ let mut runtime = Runtime::instantiate(wasm)?;
+ let tests = vec![(2, 4), (10, 20), (1, 2)];
+
+ for (arg, want) in tests {
+ let args = vec![Value::I32(arg)];
+ let result = runtime.call("call_doubler", args)?;
+ assert_eq!(result, Some(Value::I32(want)));
+ }
+ Ok(())
+ }
}
running 9 tests
test binary::module::tests::decode_func_local ... ok
test binary::module::tests::decode_simplest_module ... ok
test execution::runtime::tests::not_found_export_function ... ok
test binary::module::tests::decode_func_param ... ok
test binary::module::tests::decode_func_call ... ok
test binary::module::tests::decode_func_add ... ok
test execution::runtime::tests::func_call ... ok
test execution::runtime::tests::execute_i32_add ... ok
test binary::module::tests::decode_simplest_func ... ok
Summary
In this chapter, the implementation of function calls was completed. In the next chapter, we will implement the execution of imported external functions.
Implementation external function execution
In this chapter, we will extend the implementation from the previous chapter to include the functionality of executing external functions.
Ultimately, by registering closures in the Wasm Runtime, we will be able to execute external functions.
#![allow(unused)] fn main() { runtime.add_import("env", "add", |_, args| { let arg = args[0]; Ok(Some(arg + arg)) })?; let args = vec![Value::I32(arg)]; let result = runtime.call("call_add", args)?; assert_eq!(result, Some(Value::I32(want))); }
Implementation of Import Section Decoding
As explained in the chapter on Wasm Binary Structure, the Wasm Runtime has an import feature.
The
Import Sectiondefines the area where information for importing external entities such as memory and functions located outside the module is specified. External entities refer to memory and functions provided by other modules or the Runtime.
By the end of this section, you will be able to decode the following WAT.
Although it is similar to processing the Export Section, you should be able to understand it smoothly.
src/fixtures/import.wat
(module
(func $add (import "env" "add") (param i32) (result i32))
(func (export "call_add") (param i32) (result i32)
(local.get 0)
(call $add)
)
)
The binary structure is as follows.
; section "Import" (2)
0000010: 02 ; section code
0000011: 0b ; section size
0000012: 01 ; num imports
; import header 0
0000013: 03 ; string length
0000014: 656e 76 ; import module name (env)
0000017: 03 ; string length
0000018: 6164 64 ; import field name (add)
000001b: 00 ; import kind
000001c: 00 ; import signature index
First, add Import similar to Export.
src/binary/types.rs
diff --git a/src/binary/types.rs b/src/binary/types.rs
index 191c34b..64912f8 100644
--- a/src/binary/types.rs
+++ b/src/binary/types.rs
@@ -36,3 +36,15 @@ pub struct Export {
pub name: String,
pub desc: ExportDesc,
}
+
+#[derive(Debug, Clone, PartialEq, Eq)]
+pub enum ImportDesc {
+ Func(u32),
+}
+
+#[derive(Debug, PartialEq, Eq)]
+pub struct Import {
+ pub module: String,
+ pub field: String,
+ pub desc: ImportDesc,
+}
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index 5bf739d..dbcb30e 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -2,7 +2,7 @@ use super::{
instruction::Instruction,
opcode::Opcode,
section::{Function, SectionCode},
- types::{Export, ExportDesc, FuncType, FunctionLocal, ValueType},
+ types::{Export, ExportDesc, FuncType, FunctionLocal, Import, ValueType},
};
use nom::{
bytes::complete::{tag, take},
@@ -22,6 +22,7 @@ pub struct Module {
pub function_section: Option<Vec<u32>>,
pub code_section: Option<Vec<Function>>,
pub export_section: Option<Vec<Export>>,
+ pub import_section: Option<Vec<Import>>,
}
impl Default for Module {
@@ -33,6 +34,7 @@ impl Default for Module {
function_section: None,
code_section: None,
export_section: None,
+ import_section: None,
}
}
}
Next, extract the part that decodes strings into decode_name(...).
As you can see in the binary, module names and function names are strings, so it is necessary to decode strings multiple times, making it reusable.
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index dbcb30e..7430fbe 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -214,9 +214,7 @@ fn decode_export_section(input: &[u8]) -> IResult<&[u8], Vec<Export>> {
let mut exports = vec![];
for _ in 0..count {
- let (rest, name_len) = leb128_u32(input)?;
- let (rest, name_bytes) = take(name_len)(rest)?;
- let name = String::from_utf8(name_bytes.to_vec()).expect("invalid utf-8 string");
+ let (rest, name) = decode_name(input)?;
let (rest, export_kind) = le_u8(rest)?;
let (rest, idx) = leb128_u32(rest)?;
let desc = match export_kind {
@@ -230,6 +228,15 @@ fn decode_export_section(input: &[u8]) -> IResult<&[u8], Vec<Export>> {
Ok((input, exports))
}
+fn decode_name(input: &[u8]) -> IResult<&[u8], String> {
+ let (input, size) = leb128_u32(input)?;
+ let (input, name) = take(size)(input)?;
+ Ok((
+ input,
+ String::from_utf8(name.to_vec()).expect("invalid utf-8 string"),
+ ))
+}
+
#[cfg(test)]
mod tests {
use crate::binary::{
Then, implement the decoding process.
It is similar to decoding the Import Section.
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index 7430fbe..e3253de 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -2,7 +2,7 @@ use super::{
instruction::Instruction,
opcode::Opcode,
section::{Function, SectionCode},
- types::{Export, ExportDesc, FuncType, FunctionLocal, Import, ValueType},
+ types::{Export, ExportDesc, FuncType, FunctionLocal, Import, ImportDesc, ValueType},
};
use nom::{
bytes::complete::{tag, take},
@@ -83,6 +83,10 @@ impl Module {
let (_, exports) = decode_export_section(section_contents)?;
module.export_section = Some(exports);
}
+ SectionCode::Import => {
+ let (_, imports) = decode_import_section(section_contents)?;
+ module.import_section = Some(imports);
+ }
_ => todo!(),
};
@@ -228,6 +232,34 @@ fn decode_export_section(input: &[u8]) -> IResult<&[u8], Vec<Export>> {
Ok((input, exports))
}
+fn decode_import_section(input: &[u8]) -> IResult<&[u8], Vec<Import>> {
+ let (mut input, count) = leb128_u32(input)?;
+ let mut imports = vec![];
+
+ for _ in 0..count {
+ let (rest, module) = decode_name(input)?;
+ let (rest, field) = decode_name(rest)?;
+ let (rest, import_kind) = le_u8(rest)?;
+ let (rest, desc) = match import_kind {
+ 0x00 => {
+ let (rest, idx) = leb128_u32(rest)?;
+ (rest, ImportDesc::Func(idx))
+ }
+ _ => unimplemented!("unsupported import kind: {:X}", import_kind),
+ };
+
+ imports.push(Import {
+ module,
+ field,
+ desc,
+ });
+
+ input = rest;
+ }
+
+ Ok((&[], imports))
+}
+
fn decode_name(input: &[u8]) -> IResult<&[u8], String> {
let (input, size) = leb128_u32(input)?;
let (input, name) = take(size)(input)?;
Next, add test code to ensure that the decoding implementation is correct.
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index e3253de..2a8dbfa 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -275,7 +275,7 @@ mod tests {
instruction::Instruction,
module::Module,
section::Function,
- types::{Export, ExportDesc, FuncType, FunctionLocal, ValueType},
+ types::{Export, ExportDesc, FuncType, FunctionLocal, Import, ImportDesc, ValueType},
};
use anyhow::Result;
@@ -427,4 +427,39 @@ mod tests {
);
Ok(())
}
+
+ #[test]
+ fn decode_import() -> Result<()> {
+ let wasm = wat::parse_file("src/fixtures/import.wat")?;
+ let module = Module::new(&wasm)?;
+ assert_eq!(
+ module,
+ Module {
+ type_section: Some(vec![FuncType {
+ params: vec![ValueType::I32],
+ results: vec![ValueType::I32],
+ }]),
+ import_section: Some(vec![Import {
+ module: "env".into(),
+ field: "add".into(),
+ desc: ImportDesc::Func(0),
+ }]),
+ export_section: Some(vec![Export {
+ name: "call_add".into(),
+ desc: ExportDesc::Func(1),
+ }]),
+ function_section: Some(vec![0]),
+ code_section: Some(vec![Function {
+ locals: vec![],
+ code: vec![
+ Instruction::LocalGet(0),
+ Instruction::Call(0),
+ Instruction::End
+ ],
+ }]),
+ ..Default::default()
+ }
+ );
+ Ok(())
+ }
}
running 10 tests
test binary::module::tests::decode_simplest_module ... ok
test binary::module::tests::decode_func_param ... ok
test binary::module::tests::decode_simplest_func ... ok
test binary::module::tests::decode_func_local ... ok
test binary::module::tests::decode_func_call ... ok
test binary::module::tests::decode_func_add ... ok
test execution::runtime::tests::not_found_export_function ... ok
test binary::module::tests::decode_import ... ok
test execution::runtime::tests::func_call ... ok
test execution::runtime::tests::execute_i32_add ... ok
Implementation of External Function Execution
Similar to internal functions, when executing external functions, you need ExternalFuncInst that holds information (module name, function name, function signature).
src/execution/store.rs
diff --git a/src/execution/store.rs b/src/execution/store.rs
index 3f6ecb2..922f2b1 100644
--- a/src/execution/store.rs
+++ b/src/execution/store.rs
@@ -19,8 +19,17 @@ pub struct InternalFuncInst {
pub code: Func,
}
+#[derive(Debug, Clone)]
+pub struct ExternalFuncInst {
+ pub module: String,
+ pub func: String,
+ pub func_type: FuncType,
+}
+
+#[derive(Clone)]
pub enum FuncInst {
Internal(InternalFuncInst),
+ External(ExternalFuncInst),
}
pub struct ExportInst {
Unlike internal functions, external functions are imported, so their actual implementation is outside the Wasm binary. Therefore, from the perspective of the Wasm binary, it is just calling some function.
In Rust terms, it is like doing the following:
extern "C" { fn double(x: i32) -> i32; } fn main() { unsafe { double(10) }; }
The decoding process is similar to the Code Section, where it retrieves module names, function names, and signature information.
src/execution/store.rs
diff --git a/src/execution/store.rs b/src/execution/store.rs
index 922f2b1..5666a39 100644
--- a/src/execution/store.rs
+++ b/src/execution/store.rs
@@ -3,7 +3,7 @@ use std::collections::HashMap;
use crate::binary::{
instruction::Instruction,
module::Module,
- types::{ExportDesc, FuncType, ValueType},
+ types::{ExportDesc, FuncType, ImportDesc, ValueType},
};
use anyhow::{bail, Result};
@@ -57,6 +57,33 @@ impl Store {
let mut funcs = vec![];
+ if let Some(ref import_section) = module.import_section {
+ for import in import_section {
+ let module_name = import.module.clone();
+ let field = import.field.clone();
+ let func_type = match import.desc {
+ ImportDesc::Func(type_idx) => {
+ let Some(ref func_types) = module.type_section else {
+ bail!("not found type_section")
+ };
+
+ let Some(func_type) = func_types.get(type_idx as usize) else {
+ bail!("not found func type in type_section")
+ };
+
+ func_type.clone()
+ }
+ };
+
+ let func = FuncInst::External(ExternalFuncInst {
+ module: module_name,
+ func: field,
+ func_type,
+ });
+ funcs.push(func);
+ }
+ }
+
if let Some(ref code_section) = module.code_section {
for (func_body, type_idx) in code_section.iter().zip(func_type_idxs.into_iter()) {
let Some(ref func_types) = module.type_section else {
Next, we will register external functions in the Runtime so that they can be executed from Wasm. First, define a type alias for a data structure that can reverse lookup functions based on module names and function names.
src/execution/import.rs
#![allow(unused)] fn main() { use anyhow::Result; use std::collections::HashMap; use super::{store::Store, value::Value}; pub type ImportFunc = Box<dyn FnMut(&mut Store, Vec<Value>) -> Result<Option<Value>>>; pub type Import = HashMap<String, HashMap<String, ImportFunc>>; }
src/execution.rs
diff --git a/src/execution.rs b/src/execution.rs
index acbafa4..5d6aec6 100644
--- a/src/execution.rs
+++ b/src/execution.rs
@@ -1,3 +1,4 @@
+pub mod import;
pub mod runtime;
pub mod store;
pub mod value;
ImportFunc represents the function being registered and is a closure.
To implement memory manipulation in the next chapter, it takes a &mut Store as an interface.
Import is the type of data structure used for reverse lookup.
Next, add the import field to be able to hold import information in the Wasm Runtime.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 5e2772f..cf7bcb9 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -1,5 +1,6 @@
use super::{
- store::{FuncInst, InternalFuncInst, Store},
+ import::Import,
+ store::{ExternalFuncInst, FuncInst, InternalFuncInst, Store},
value::Value,
};
use crate::binary::{
@@ -23,6 +24,7 @@ pub struct Runtime {
pub store: Store,
pub stack: Vec<Value>,
pub call_stack: Vec<Frame>,
+ pub import: Import,
}
impl Runtime {
With this, it is now possible to reverse lookup functions based on import information, so the process of executing external functions is implemented as follows.
The invoke_external(...) function is responsible for executing external functions, and all it does is call the closure obtained by reverse lookup with the module name and function name.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index cf7bcb9..bd1a1e5 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -56,6 +56,7 @@ impl Runtime {
}
match func_inst {
FuncInst::Internal(func) => self.invoke_internal(func.clone()),
+ FuncInst::External(func) => self.invoke_external(func.clone()),
}
}
@@ -102,6 +103,20 @@ impl Runtime {
Ok(None)
}
+ fn invoke_external(&mut self, func: ExternalFuncInst) -> Result<Option<Value>> {
+ let args = self
+ .stack
+ .split_off(self.stack.len() - func.func_type.params.len());
+ let module = self
+ .import
+ .get_mut(&func.module)
+ .ok_or(anyhow!("not found module"))?;
+ let import_func = module
+ .get_mut(&func.func)
+ .ok_or(anyhow!("not found function"))?;
+ import_func(&mut self.store, args)
+ }
+
fn execute(&mut self) -> Result<()> {
loop {
let Some(frame) = self.call_stack.last_mut() else {
@@ -139,8 +154,14 @@ impl Runtime {
let Some(func) = self.store.funcs.get(*idx as usize) else {
bail!("not found func");
};
- match func {
- FuncInst::Internal(func) => self.push_frame(&func.clone()),
+ let func_inst = func.clone();
+ match func_inst {
+ FuncInst::Internal(func) => self.push_frame(&func),
+ FuncInst::External(func) => {
+ if let Some(value) = self.invoke_external(func)? {
+ self.stack.push(value);
+ }
+ }
}
}
}
Now that external functions can be executed, the next step is to add a function to register external functions in the Runtime.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index bd1a1e5..41e50c6 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -37,6 +37,17 @@ impl Runtime {
})
}
+ pub fn add_import(
+ &mut self,
+ module_name: impl Into<String>,
+ func_name: impl Into<String>,
+ func: impl FnMut(&mut Store, Vec<Value>) -> Result<Option<Value>> + 'static,
+ ) -> Result<()> {
+ let import = self.import.entry(module_name.into()).or_default();
+ import.insert(func_name.into(), Box::new(func));
+ Ok(())
+ }
+
pub fn call(&mut self, name: impl Into<String>, args: Vec<Value>) -> Result<Option<Value>> {
let idx = match self
.store
Finally, add tests to ensure that everything works correctly.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 41e50c6..437cef3 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -241,4 +241,22 @@ mod tests {
}
Ok(())
}
+
+ #[test]
+ fn call_imported_func() -> Result<()> {
+ let wasm = wat::parse_file("src/fixtures/import.wat")?;
+ let mut runtime = Runtime::instantiate(wasm)?;
+ runtime.add_import("env", "add", |_, args| {
+ let arg = args[0];
+ Ok(Some(arg + arg))
+ })?;
+ let tests = vec![(2, 4), (10, 20), (1, 2)];
+
+ for (arg, want) in tests {
+ let args = vec![Value::I32(arg)];
+ let result = runtime.call("call_add", args)?;
+ assert_eq!(result, Some(Value::I32(want)));
+ }
+ Ok(())
+ }
}
running 11 tests
test binary::module::tests::decode_func_param ... ok
test binary::module::tests::decode_simplest_module ... ok
test binary::module::tests::decode_func_local ... ok
test binary::module::tests::decode_func_add ... ok
test binary::module::tests::decode_func_call ... ok
test binary::module::tests::decode_import ... ok
test binary::module::tests::decode_simplest_func ... ok
test execution::runtime::tests::execute_i32_add ... ok
test execution::runtime::tests::call_imported_func ... ok
test execution::runtime::tests::func_call ... ok
test execution::runtime::tests::not_found_export_function ... ok
Also, make sure that an error occurs properly if an external function is not found.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 437cef3..3c492bc 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -259,4 +259,14 @@ mod tests {
}
Ok(())
}
+
+ #[test]
+ fn not_found_imported_func() -> Result<()> {
+ let wasm = wat::parse_file("src/fixtures/import.wat")?;
+ let mut runtime = Runtime::instantiate(wasm)?;
+ runtime.add_import("env", "fooooo", |_, _| Ok(None))?;
+ let result = runtime.call("call_add", vec![Value::I32(1)]);
+ assert!(result.is_err());
+ Ok(())
+ }
}
running 1 test
test execution::runtime::tests::not_found_imported_func ... ok
Summary
In this chapter, the implementation has progressed to the point where external functions can be executed.
Gradually, the Wasm Runtime is taking shape.
In fact, being able to execute external functions means being able to output "Hello, World", but this book implements WASI properly for output.
Implementation additional instructions
In this chapter, we need the following instructions for the features we are about to implement, so let's implement them first.
| Instruction | Description |
|---|---|
local.set | pop a value from the stack and place it in a local variable |
i32.const | push the value of the operand onto the stack |
i32.store | pop a value from the stack and write it to memory |
Implementation of local.set
The local.set instruction has an operand that allows specifying where to place the value in a local variable.
src/binary/opcode.rs
diff --git a/src/binary/opcode.rs b/src/binary/opcode.rs
index 5d0a2b7..55d30c1 100644
--- a/src/binary/opcode.rs
+++ b/src/binary/opcode.rs
@@ -4,6 +4,7 @@ use num_derive::FromPrimitive;
pub enum Opcode {
End = 0x0B,
LocalGet = 0x20,
+ LocalSet = 0x21,
I32Add = 0x6A,
Call = 0x10,
}
src/binary/instruction.rs
diff --git a/src/binary/instruction.rs b/src/binary/instruction.rs
index c9c6584..81d0d95 100644
--- a/src/binary/instruction.rs
+++ b/src/binary/instruction.rs
@@ -2,6 +2,7 @@
pub enum Instruction {
End,
LocalGet(u32),
+ LocalSet(u32),
I32Add,
Call(u32),
}
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index 40f20fd..8426948 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -217,6 +217,10 @@ fn decode_instructions(input: &[u8]) -> IResult<&[u8], Instruction> {
let (rest, idx) = leb128_u32(input)?;
(rest, Instruction::LocalGet(idx))
}
+ Opcode::LocalSet => {
+ let (rest, idx) = leb128_u32(input)?;
+ (rest, Instruction::LocalSet(idx))
+ }
Opcode::I32Add => (input, Instruction::I32Add),
Opcode::End => (input, Instruction::End),
Opcode::Call => {
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 3c492bc..c52de7b 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -154,6 +154,13 @@ impl Runtime {
};
self.stack.push(*value);
}
+ Instruction::LocalSet(idx) => {
+ let Some(value) = self.stack.pop() else {
+ bail!("not found value in the stack");
+ };
+ let idx = *idx as usize;
+ frame.locals[idx] = value;
+ }
Instruction::I32Add => {
let (Some(right), Some(left)) = (self.stack.pop(), self.stack.pop()) else {
bail!("not found any value in the stack");
The operation is simple, placing the pop value at the specified index of frame.locals.
Implementation of i32.const
i32.const has an operand with a value that is pushed onto the stack.
src/binary/opcode.rs
diff --git a/src/binary/opcode.rs b/src/binary/opcode.rs
index 55d30c1..1eb29fd 100644
--- a/src/binary/opcode.rs
+++ b/src/binary/opcode.rs
@@ -5,6 +5,7 @@ pub enum Opcode {
End = 0x0B,
LocalGet = 0x20,
LocalSet = 0x21,
+ I32Const = 0x41,
I32Add = 0x6A,
Call = 0x10,
}
src/binary/instruction.rs
diff --git a/src/binary/instruction.rs b/src/binary/instruction.rs
index 81d0d95..0e392c5 100644
--- a/src/binary/instruction.rs
+++ b/src/binary/instruction.rs
@@ -3,6 +3,7 @@ pub enum Instruction {
End,
LocalGet(u32),
LocalSet(u32),
+ I32Const(i32),
I32Add,
Call(u32),
}
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index 8426948..26b56b3 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -14,7 +14,7 @@ use nom::{
sequence::pair,
IResult,
};
-use nom_leb128::leb128_u32;
+use nom_leb128::{leb128_i32, leb128_u32};
use num_traits::FromPrimitive as _;
#[derive(Debug, PartialEq, Eq)]
@@ -221,6 +221,10 @@ fn decode_instructions(input: &[u8]) -> IResult<&[u8], Instruction> {
let (rest, idx) = leb128_u32(input)?;
(rest, Instruction::LocalSet(idx))
}
+ Opcode::I32Const => {
+ let (rest, value) = leb128_i32(input)?;
+ (rest, Instruction::I32Const(value))
+ }
Opcode::I32Add => (input, Instruction::I32Add),
Opcode::End => (input, Instruction::End),
Opcode::Call => {
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index c52de7b..9044e25 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -161,6 +161,7 @@ impl Runtime {
let idx = *idx as usize;
frame.locals[idx] = value;
}
+ Instruction::I32Const(value) => self.stack.push(Value::I32(*value)),
Instruction::I32Add => {
let (Some(right), Some(left)) = (self.stack.pop(), self.stack.pop()) else {
bail!("not found any value in the stack");
Add tests combining with local.set to ensure the implementation is correct.
src/fixtures/i32_const.wat
(module
(func $i32_const (result i32)
(i32.const 42)
)
(export "i32_const" (func $i32_const))
)
src/fixtures/local_set.wat
(module
(func $local_set (result i32)
(local $x i32)
(local.set $x (i32.const 42))
(local.get 0)
)
(export "local_set" (func $local_set))
)
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 9044e25..1b18d77 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -277,4 +277,22 @@ mod tests {
assert!(result.is_err());
Ok(())
}
+
+ #[test]
+ fn i32_const() -> Result<()> {
+ let wasm = wat::parse_file("src/fixtures/i32_const.wat")?;
+ let mut runtime = Runtime::instantiate(wasm)?;
+ let result = runtime.call("i32_const", vec![])?;
+ assert_eq!(result, Some(Value::I32(42)));
+ Ok(())
+ }
+
+ #[test]
+ fn local_set() -> Result<()> {
+ let wasm = wat::parse_file("src/fixtures/local_set.wat")?;
+ let mut runtime = Runtime::instantiate(wasm)?;
+ let result = runtime.call("local_set", vec![])?;
+ assert_eq!(result, Some(Value::I32(42)));
+ Ok(())
+ }
}
Implementation of i32.store decoding
i32.store is an instruction that pop a value from the stack and writes it to the specified memory address.
src/binary/opcode.rs
diff --git a/src/binary/opcode.rs b/src/binary/opcode.rs
index 1eb29fd..1e0931b 100644
--- a/src/binary/opcode.rs
+++ b/src/binary/opcode.rs
@@ -5,6 +5,7 @@ pub enum Opcode {
End = 0x0B,
LocalGet = 0x20,
LocalSet = 0x21,
+ I32Store = 0x36,
I32Const = 0x41,
I32Add = 0x6A,
Call = 0x10,
src/binary/instruction.rs
diff --git a/src/binary/instruction.rs b/src/binary/instruction.rs
index 0e392c5..326db0a 100644
--- a/src/binary/instruction.rs
+++ b/src/binary/instruction.rs
@@ -3,6 +3,7 @@ pub enum Instruction {
End,
LocalGet(u32),
LocalSet(u32),
+ I32Store { align: u32, offset: u32 },
I32Const(i32),
I32Add,
Call(u32),
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index 26b56b3..f55db9b 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -221,6 +221,11 @@ fn decode_instructions(input: &[u8]) -> IResult<&[u8], Instruction> {
let (rest, idx) = leb128_u32(input)?;
(rest, Instruction::LocalSet(idx))
}
+ Opcode::I32Store => {
+ let (rest, align) = leb128_u32(input)?;
+ let (rest, offset) = leb128_u32(rest)?;
+ (rest, Instruction::I32Store { align, offset })
+ }
Opcode::I32Const => {
let (rest, value) = leb128_i32(input)?;
(rest, Instruction::I32Const(value))
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index bcb8288..b5b7417 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -183,6 +183,7 @@ impl Runtime {
}
}
}
+ _ => todo!(), // Instruction processing is set to TODO to avoid compilation errors
}
}
Ok(())
The operand of i32.store consists of an offset and alignment value, where address + offset becomes the actual location to write the value.
Alignment is necessary for memory boundary checks, but it is out of the scope of this document, so we decode it but do not use it specifically.
With the decoding of the instruction in place, add tests to ensure the implementation is correct.
src/execution/runtime.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index f55db9b..c2a8c39 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -604,4 +604,35 @@ mod tests {
}
Ok(())
}
+
+ #[test]
+ fn decode_i32_store() -> Result<()> {
+ let wasm = wat::parse_str(
+ "(module (func (i32.store offset=4 (i32.const 4))))",
+ )?;
+ let module = Module::new(&wasm)?;
+ assert_eq!(
+ module,
+ Module {
+ type_section: Some(vec![FuncType {
+ params: vec![],
+ results: vec![],
+ }]),
+ function_section: Some(vec![0]),
+ code_section: Some(vec![Function {
+ locals: vec![],
+ code: vec![
+ Instruction::I32Const(4),
+ Instruction::I32Store {
+ align: 2,
+ offset: 4
+ },
+ Instruction::End
+ ],
+ }]),
+ ..Default::default()
+ }
+ );
+ Ok(())
+ }
}
running 18 tests
test binary::module::tests::decode_simplest_module ... ok
test binary::module::tests::decode_simplest_func ... ok
test binary::module::tests::decode_func_param ... ok
test binary::module::tests::decode_memory ... ok
test binary::module::tests::decode_func_add ... ok
test binary::module::tests::decode_i32_store ... ok
test binary::module::tests::decode_func_call ... ok
test binary::module::tests::decode_import ... ok
test binary::module::tests::decode_func_local ... ok
test binary::module::tests::decode_data ... ok
test execution::runtime::tests::call_imported_func ... ok
test execution::runtime::tests::execute_i32_add ... ok
test execution::runtime::tests::i32_const ... ok
test execution::runtime::tests::not_found_export_function ... ok
test execution::runtime::tests::func_call ... ok
test execution::runtime::tests::local_set ... ok
test execution::runtime::tests::not_found_imported_func ... ok
test execution::store::test::init_memory ... ok
Memory is required to implement the i32.store instruction, so we will implement the instruction along with memory initialization in the next chapter.
Summary
In this chapter, additional instructions were implemented. In the next chapter, we will implement memory initialization functionality in the Wasm Runtime to handle memory.
Implementation memory initialization
In this chapter, we will implement the functionality to initialize the memory held by the Wasm Runtime and place data in it.
Ultimately, we will be able to initialize the memory of the Wasm Runtime with the following WAT.
We will also implement the i32.store instruction left in the previous chapter.
(module
(memory 1)
(data (i32.const 0) "hello")
(data (i32.const 5) "world")
)
Implementation of Memory Section Decoding
First, we will work on decoding the Memory Section.
The Memory Section contains information on how much memory to allocate during Wasm Runtime initialization, so by decoding this section, we will be able to allocate memory.
For detailed binary structure, refer to the chapter on Wasm Binary Structure.
First, define the Memory that holds memory information.
/src/binary/types.rs
diff --git a/src/binary/types.rs b/src/binary/types.rs
index 64912f8..3d620f3 100644
--- a/src/binary/types.rs
+++ b/src/binary/types.rs
@@ -48,3 +48,14 @@ pub struct Import {
pub field: String,
pub desc: ImportDesc,
}
+
+#[derive(Debug, Clone, PartialEq, Eq)]
+pub struct Limits {
+ pub min: u32,
+ pub max: Option<u32>,
+}
+
+#[derive(Debug, Clone, PartialEq, Eq)]
+pub struct Memory {
+ pub limits: Limits,
+}
Next, implement the decoding process.
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index 2a8dbfa..d7b56ba 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -2,7 +2,9 @@ use super::{
instruction::Instruction,
opcode::Opcode,
section::{Function, SectionCode},
- types::{Export, ExportDesc, FuncType, FunctionLocal, Import, ImportDesc, ValueType},
+ types::{
+ Export, ExportDesc, FuncType, FunctionLocal, Import, ImportDesc, Limits, Memory, ValueType,
+ },
};
use nom::{
bytes::complete::{tag, take},
@@ -18,6 +20,7 @@ use num_traits::FromPrimitive as _;
pub struct Module {
pub magic: String,
pub version: u32,
+ pub memory_section: Option<Vec<Memory>>,
pub type_section: Option<Vec<FuncType>>,
pub function_section: Option<Vec<u32>>,
pub code_section: Option<Vec<Function>>,
@@ -30,6 +33,7 @@ impl Default for Module {
Self {
magic: "\0asm".to_string(),
version: 1,
+ memory_section: None,
type_section: None,
function_section: None,
code_section: None,
@@ -67,6 +71,10 @@ impl Module {
SectionCode::Custom => {
// skip
}
+ SectionCode::Memory => {
+ let (_, memory) = decode_memory_section(section_contents)?;
+ module.memory_section = Some(vec![memory]);
+ }
SectionCode::Type => {
let (_, types) = decode_type_section(section_contents)?;
module.type_section = Some(types);
@@ -260,6 +268,24 @@ fn decode_import_section(input: &[u8]) -> IResult<&[u8], Vec<Import>> {
Ok((&[], imports))
}
+fn decode_memory_section(input: &[u8]) -> IResult<&[u8], Memory> {
+ let (input, _) = leb128_u32(input)?; // 1
+ let (_, limits) = decode_limits(input)?;
+ Ok((input, Memory { limits }))
+}
+
+fn decode_limits(input: &[u8]) -> IResult<&[u8], Limits> {
+ let (input, (flags, min)) = pair(leb128_u32, leb128_u32)(input)?; // 2
+ let max = if flags == 0 { // 3
+ None
+ } else {
+ let (_, max) = leb128_u32(input)?;
+ Some(max)
+ };
+
+ Ok((input, Limits { min, max }))
+}
+
fn decode_name(input: &[u8]) -> IResult<&[u8], String> {
let (input, size) = leb128_u32(input)?;
let (input, name) = take(size)(input)?;
The decoding process does the following:
- Retrieve the number of memories
- In version 1, only one memory can be handled, so it is currently being skipped
- Read
flagsandminflagsis a value used to check if there is an upper limit specification for the number of pagesminis the initial number of pages
- If
flagsis0, it means there is no specification for the upper limit of pages, and if it is1, there is a limit, so read that value
With this information necessary for memory allocation gathered, the next step is to implement the ability for the Runtime to have memory.
src/execution/store.rs
diff --git a/src/execution/store.rs b/src/execution/store.rs
index 5666a39..efadc19 100644
--- a/src/execution/store.rs
+++ b/src/execution/store.rs
@@ -7,6 +7,8 @@ use crate::binary::{
};
use anyhow::{bail, Result};
+pub const PAGE_SIZE: u32 = 65536; // 64KiB
+
#[derive(Clone)]
pub struct Func {
pub locals: Vec<ValueType>,
@@ -42,10 +44,17 @@ pub struct ModuleInst {
pub exports: HashMap<String, ExportInst>,
}
+#[derive(Default, Debug, Clone)]
+pub struct MemoryInst {
+ pub data: Vec<u8>,
+ pub max: Option<u32>,
+}
+
#[derive(Default)]
pub struct Store {
pub funcs: Vec<FuncInst>,
pub module: ModuleInst,
+ pub memories: Vec<MemoryInst>,
}
impl Store {
@@ -56,6 +65,7 @@ impl Store {
};
let mut funcs = vec![];
+ let mut memories = vec![];
if let Some(ref import_section) = module.import_section {
for import in import_section {
@@ -125,8 +135,20 @@ impl Store {
};
let module_inst = ModuleInst { exports };
+ if let Some(ref sections) = module.memory_section {
+ for memory in sections {
+ let min = memory.limits.min * PAGE_SIZE; // 1
+ let memory = MemoryInst {
+ data: vec![0; min as usize], // 2
+ max: memory.limits.max,
+ };
+ memories.push(memory);
+ }
+ }
+
Ok(Self {
funcs,
+ memories,
module: module_inst,
})
}
MemoryInst represents the actual memory, where data is the memory area that the Wasm Runtime can operate on.
As you can see, it is simply a variable-length array.
The memory that the Wasm Runtime can operate on is only MemoryInst::data, so there will be no overlap with memory areas of other programs, which is one of the reasons it is considered secure.
The memory allocation process does the following:
- Since
memory.limits.minrepresents the number of pages, calculate the minimum amount of memory to allocate by multiplying it with the page size - Initialize an array of the calculated size with zeros
Additionally, although not used extensively in the scope of this implementation, memory.limits.max is used for checking the upper limit of memory.
In Wasm, the memory.grow instruction is used to increase memory, and this is used to check if the increase exceeds the allowable limit.
Next, confirm that decoding works correctly in tests.
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index 935654b..3e59d35 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -301,7 +301,10 @@ mod tests {
instruction::Instruction,
module::Module,
section::Function,
- types::{Export, ExportDesc, FuncType, FunctionLocal, Import, ImportDesc, ValueType},
+ types::{
+ Export, ExportDesc, FuncType, FunctionLocal, Import, ImportDesc, Limits, Memory,
+ ValueType,
+ },
};
use anyhow::Result;
@@ -488,4 +491,29 @@ mod tests {
);
Ok(())
}
+
+ #[test]
+ fn decode_memory() -> Result<()> {
+ let tests = vec![
+ ("(module (memory 1))", Limits { min: 1, max: None }),
+ (
+ "(module (memory 1 2))",
+ Limits {
+ min: 1,
+ max: Some(2),
+ },
+ ),
+ ];
+ for (wasm, limits) in tests {
+ let module = Module::new(&wat::parse_str(wasm)?)?;
+ assert_eq!(
+ module,
+ Module {
+ memory_section: Some(vec![Memory { limits }]),
+ ..Default::default()
+ }
+ );
+ }
+ Ok(())
+ }
}
running 13 tests
test binary::module::tests::decode_simplest_module ... ok
test binary::module::tests::decode_memory ... ok
test binary::module::tests::decode_func_param ... ok
test binary::module::tests::decode_simplest_func ... ok
test binary::module::tests::decode_func_call ... ok
test execution::runtime::tests::not_found_export_function ... ok
test binary::module::tests::decode_func_add ... ok
test execution::runtime::tests::execute_i32_add ... ok
test execution::runtime::tests::func_call ... ok
test binary::module::tests::decode_func_local ... ok
test binary::module::tests::decode_import ... ok
test execution::runtime::tests::not_found_imported_func ... ok
test execution::runtime::tests::call_imported_func ... ok
Implementation of Data Section Decoding
The Data Section defines the area where data to be placed in memory after memory allocation by the Runtime is specified. We will proceed with implementing the decoding to place this data in memory.
For detailed binary structure, refer to the Wasm Binary Structure.
First, prepare the following structure.
src/binary/types.rs
diff --git a/src/binary/types.rs b/src/binary/types.rs
index 3d620f3..bff2cd4 100644
--- a/src/binary/types.rs
+++ b/src/binary/types.rs
@@ -59,3 +59,10 @@ pub struct Limits {
pub struct Memory {
pub limits: Limits,
}
+
+#[derive(Debug, Clone, PartialEq, Eq)]
+pub struct Data {
+ pub memory_index: u32,
+ pub offset: u32,
+ pub init: Vec<u8>,
+}
Each field is as follows:
memory_index: Points to the memory where the data will be placed- In version 1, since only one memory can be handled, it will generally be
0
- In version 1, since only one memory can be handled, it will generally be
offset: The starting position in memory where the data will be placed; if0, the data will be placed starting from byte0init: The byte sequence of the data to be placed
Next, implement the decoding process.
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index 3e59d35..46db8dc 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -3,7 +3,8 @@ use super::{
opcode::Opcode,
section::{Function, SectionCode},
types::{
- Export, ExportDesc, FuncType, FunctionLocal, Import, ImportDesc, Limits, Memory, ValueType,
+ Data, Export, ExportDesc, FuncType, FunctionLocal, Import, ImportDesc, Limits, Memory,
+ ValueType,
},
};
use nom::{
@@ -21,6 +22,7 @@ pub struct Module {
pub magic: String,
pub version: u32,
pub memory_section: Option<Vec<Memory>>,
+ pub data_section: Option<Vec<Data>>,
pub type_section: Option<Vec<FuncType>>,
pub function_section: Option<Vec<u32>>,
pub code_section: Option<Vec<Function>>,
@@ -34,6 +36,7 @@ impl Default for Module {
magic: "\0asm".to_string(),
version: 1,
memory_section: None,
+ data_section: None,
type_section: None,
function_section: None,
code_section: None,
@@ -75,6 +78,10 @@ impl Module {
let (_, memory) = decode_memory_section(section_contents)?;
module.memory_section = Some(vec![memory]);
}
+ SectionCode::Data => {
+ let (_, data) = deocde_data_section(section_contents)?;
+ module.data_section = Some(data);
+ }
SectionCode::Type => {
let (_, types) = decode_type_section(section_contents)?;
module.type_section = Some(types);
@@ -95,7 +102,6 @@ impl Module {
let (_, imports) = decode_import_section(section_contents)?;
module.import_section = Some(imports);
}
- _ => todo!(),
};
remaining = rest;
@@ -286,6 +292,31 @@ fn decode_limits(input: &[u8]) -> IResult<&[u8], Limits> {
Ok((input, Limits { min, max }))
}
+fn decode_expr(input: &[u8]) -> IResult<&[u8], u32> {
+ let (input, _) = leb128_u32(input)?;
+ let (input, offset) = leb128_u32(input)?;
+ let (input, _) = leb128_u32(input)?;
+ Ok((input, offset))
+}
+
+fn deocde_data_section(input: &[u8]) -> IResult<&[u8], Vec<Data>> {
+ let (mut input, count) = leb128_u32(input)?; // 1
+ let mut data = vec![];
+ for _ in 0..count {
+ let (rest, memory_index) = leb128_u32(input)?;
+ let (rest, offset) = decode_expr(rest)?; // 2
+ let (rest, size) = leb128_u32(rest)?; // 3
+ let (rest, init) = take(size)(rest)?; // 4
+ data.push(Data {
+ memory_index,
+ offset,
+ init: init.into(),
+ });
+ input = rest;
+ }
+ Ok((input, data))
+}
+
fn decode_name(input: &[u8]) -> IResult<&[u8], String> {
let (input, size) = leb128_u32(input)?;
let (input, name) = take(size)(input)?;
In the decoding process, the following steps are performed:
- Obtain the number of
segmentsIf(data ...)becomes one segment, then if multiple are defined, processing needs to be done multiple times. - Calculate the
offsetNormally, the value ofoffsetneeds to be calculated by processing the instruction sequence indecode_expr(...), but for now, the implementation is based on the assumption of the instruction sequence[i32.const, 1, end]. - Obtain the size of the data.
- Retrieve a byte array of the size from step 3, which becomes the actual data.
Next, add tests to ensure the implementation is correct.
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index c0c1aff..40f20fd 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -333,7 +333,7 @@ mod tests {
module::Module,
section::Function,
types::{
- Export, ExportDesc, FuncType, FunctionLocal, Import, ImportDesc, Limits, Memory,
+ Data, Export, ExportDesc, FuncType, FunctionLocal, Import, ImportDesc, Limits, Memory,
ValueType,
},
};
@@ -547,4 +547,48 @@ mod tests {
}
Ok(())
}
+
+ #[test]
+ fn decode_data() -> Result<()> {
+ let tests = vec![
+ (
+ "(module (memory 1) (data (i32.const 0) \"hello\"))",
+ vec![Data {
+ memory_index: 0,
+ offset: 0,
+ init: "hello".as_bytes().to_vec(),
+ }],
+ ),
+ (
+ "(module (memory 1) (data (i32.const 0) \"hello\") (data (i32.const 5) \"world\"))",
+ vec![
+ Data {
+ memory_index: 0,
+ offset: 0,
+ init: b"hello".into(),
+ },
+ Data {
+ memory_index: 0,
+ offset: 5,
+ init: b"world".into(),
+ },
+ ],
+ ),
+ ];
+
+ for (wasm, data) in tests {
+ let module = Module::new(&wat::parse_str(wasm)?)?;
+ assert_eq!(
+ module,
+ Module {
+ memory_section: Some(vec![Memory {
+ limits: Limits { min: 1, max: None }
+ }]),
+ data_section: Some(data),
+ ..Default::default()
+ }
+ );
+ }
+ Ok(())
+ }
}
running 14 tests
test binary::module::tests::decode_simplest_module ... ok
test binary::module::tests::decode_memory ... ok
test binary::module::tests::decode_simplest_func ... ok
test binary::module::tests::decode_func_add ... ok
test binary::module::tests::decode_func_param ... ok
test binary::module::tests::decode_import ... ok
test binary::module::tests::decode_func_call ... ok
test binary::module::tests::decode_func_local ... ok
test binary::module::tests::decode_data ... ok
test execution::runtime::tests::call_imported_func ... ok
test execution::runtime::tests::execute_i32_add ... ok
test execution::runtime::tests::not_found_export_function ... ok
test execution::runtime::tests::func_call ... ok
test execution::runtime::tests::not_found_imported_func ... ok
Now that we can retrieve memory data, we will proceed to place the data on the Runtime memory.
src/execution/store.rs
diff --git a/src/execution/store.rs b/src/execution/store.rs
index efadc19..cad96ca 100644
--- a/src/execution/store.rs
+++ b/src/execution/store.rs
@@ -5,7 +5,7 @@ use crate::binary::{
module::Module,
types::{ExportDesc, FuncType, ImportDesc, ValueType},
};
-use anyhow::{bail, Result};
+use anyhow::{anyhow, bail, Result};
pub const PAGE_SIZE: u32 = 65536; // 64Ki
@@ -146,6 +146,22 @@ impl Store {
}
}
+ if let Some(ref sections) = module.data_section {
+ for data in sections {
+ let memory = memories
+ .get_mut(data.memory_index as usize)
+ .ok_or(anyhow!("not found memory"))?;
+
+ let offset = data.offset as usize;
+ let init = &data.init;
+
+ if offset + init.len() > memory.data.len() {
+ bail!("data is too large to fit in memory");
+ }
+ memory.data[offset..offset + init.len()].copy_from_slice(init);
+ }
+ }
+
Ok(Self {
funcs,
memories,
The process is simple, copying the data from the Data Section to the specified location in memory.
Finally, add tests to ensure the implementation is correct.
src/execution/store.rs
diff --git a/src/execution/store.rs b/src/execution/store.rs
index cad96ca..1bb1192 100644
--- a/src/execution/store.rs
+++ b/src/execution/store.rs
@@ -169,3 +169,32 @@ impl Store {
})
}
}
+
+#[cfg(test)]
+mod test {
+ use super::Store;
+ use crate::binary::module::Module;
+ use anyhow::Result;
+
+ #[test]
+ fn init_memory() -> Result<()> {
+ let wasm = wat::parse_file("src/fixtures/memory.wat")?;
+ let module = Module::new(&wasm)?;
+ let store = Store::new(module)?;
+ assert_eq!(store.memories.len(), 1);
+ assert_eq!(store.memories[0].data.len(), 65536);
+ assert_eq!(&store.memories[0].data[0..5], b"hello");
+ assert_eq!(&store.memories[0].data[5..10], b"world");
+ Ok(())
+ }
+}
running 15 tests
test binary::module::tests::decode_func_param ... ok
test binary::module::tests::decode_func_local ... ok
test binary::module::tests::decode_simplest_module ... ok
test binary::module::tests::decode_simplest_func ... ok
test binary::module::tests::decode_memory ... ok
test binary::module::tests::decode_import ... ok
test binary::module::tests::decode_func_add ... ok
test execution::runtime::tests::call_imported_func ... ok
test binary::module::tests::decode_func_call ... ok
test binary::module::tests::decode_data ... ok
test execution::runtime::tests::execute_i32_add ... ok
test execution::runtime::tests::not_found_export_function ... ok
test execution::store::test::init_memory ... ok
test execution::runtime::tests::func_call ... ok
test execution::runtime::tests::not_found_imported_func ... ok
Implementation of i32.store
Now that we can initialize memory, we will implement the i32.store command.
diff --git a/src/execution/value.rs b/src/execution/value.rs
index b24fd25..21d364d 100644
--- a/src/execution/value.rs
+++ b/src/execution/value.rs
@@ -10,6 +10,15 @@ impl From<i32> for Value {
}
}
+impl From<Value> for i32 {
+ fn from(value: Value) -> Self {
+ match value {
+ Value::I32(value) => value,
+ _ => panic!("type mismatch"),
+ }
+ }
+}
+
impl From<i64> for Value {
fn from(value: i64) -> Self {
Value::I64(value)
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index b5b7417..3584fdf 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -1,3 +1,5 @@
+use std::mem::size_of;
+
use super::{
import::Import,
store::{ExternalFuncInst, FuncInst, InternalFuncInst, Store},
@@ -161,6 +163,22 @@ impl Runtime {
let idx = *idx as usize;
frame.locals[idx] = value;
}
+ Instruction::I32Store { align: _, offset } => {
+ let (Some(value), Some(addr)) = (self.stack.pop(), self.stack.pop()) else { // 1
+ bail!("not found any value in the stack");
+ };
+ let addr = Into::<i32>::into(addr) as usize;
+ let offset = (*offset) as usize;
+ let at = addr + offset; // 2
+ let end = at + size_of::<i32>(); // 3
+ let memory = self
+ .store
+ .memories
+ .get_mut(0)
+ .ok_or(anyhow!("not found memory"))?;
+ let value: i32 = value.into();
+ memory.data[at..end].copy_from_slice(&value.to_le_bytes()); // 4
+ }
Instruction::I32Const(value) => self.stack.push(Value::I32(*value)),
Instruction::I32Add => {
let (Some(right), Some(left)) = (self.stack.pop(), self.stack.pop()) else {
The instruction processing involves the following.
- Get the value and address to write from the stack to memory.
- Obtain the index of the write destination by adding the address from step 1 with the offset.
- Calculate the range for writing to memory.
- Convert the value to a little-endian byte array and copy the data to the calculated range from steps 2 and 3.
Finally, add tests to ensure the implementation is correct.
src/fixtures/i32_store.wat
(module
(memory 1)
(func $i32_store
(i32.const 0)
(i32.const 42)
(i32.store)
)
(export "i32_store" (func $i32_store))
)
In i32_store.wat, the address is 0, the value is 42, and the offset is 0, so ultimately 42 will be written to memory address 0. Therefore, the test will confirm that memory address 0 contains 42.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 19b766c..79aa5e5 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -313,4 +313,14 @@ mod tests {
assert_eq!(result, Some(Value::I32(42)));
Ok(())
}
+
+ #[test]
+ fn i32_store() -> Result<()> {
+ let wasm = wat::parse_file("src/fixtures/i32_store.wat")?;
+ let mut runtime = Runtime::instantiate(wasm)?;
+ runtime.call("i32_store", vec![])?;
+ let memory = &runtime.store.memories[0].data;
+ assert_eq!(memory[0], 42);
+ Ok(())
+ }
}
running 19 tests
test binary::module::tests::decode_func_param ... ok
test binary::module::tests::decode_simplest_func ... ok
test binary::module::tests::decode_simplest_module ... ok
test binary::module::tests::decode_i32_store ... ok
test binary::module::tests::decode_import ... ok
test binary::module::tests::decode_func_call ... ok
test binary::module::tests::decode_func_local ... ok
test binary::module::tests::decode_func_add ... ok
test binary::module::tests::decode_memory ... ok
test binary::module::tests::decode_data ... ok
test execution::runtime::tests::execute_i32_add ... ok
test execution::runtime::tests::i32_const ... ok
test execution::runtime::tests::call_imported_func ... ok
test execution::runtime::tests::func_call ... ok
test execution::runtime::tests::i32_store ... ok
test execution::runtime::tests::local_set ... ok
test execution::runtime::tests::not_found_export_function ... ok
test execution::runtime::tests::not_found_imported_func ... ok
test execution::store::test::init_memory ... ok
Summary
In this chapter, the functionality for initializing memory has been implemented.
With this, we can now place arbitrary data on memory, so in the next chapter, we will place Hello, World! on memory and work towards being able to output it.
Implement print "Hello, World"
In this chapter, we will implement the fd_write function of WASI to be able to output Hello, World!.
Eventually, we will be able to execute the following WAT.
src/fixtures/hello_world.wat
(module
(import "wasi_snapshot_preview1" "fd_write"
(func $fd_write (param i32 i32 i32 i32) (result i32))
)
(memory 1)
(data (i32.const 0) "Hello, World!\n")
(func $hello_world (result i32)
(local $iovs i32)
(i32.store (i32.const 16) (i32.const 0))
(i32.store (i32.const 20) (i32.const 14))
(local.set $iovs (i32.const 16))
(call $fd_write
(i32.const 1)
(local.get $iovs)
(i32.const 1)
(i32.const 24)
)
)
(export "_start" (func $hello_world))
)
Implementation of WASI's fd_write()
WASI has not yet reached version 1 and has versions 0.1 and 0.2.
0.1 is commonly referred to as wasi_snapshot_preview1 and mainly defines system call functions.
For more details, refer to here.
The fd_write() defined in wasi_snapshot_preview1 reads data from the Wasm Runtime memory and writes data to standard output or standard error output.
Therefore, by implementing this function, we can complete the Wasm Runtime capable of outputting Hello, World!.
Let's take a look at the import of the WAT at the beginning again.
(import "wasi_snapshot_preview1" "fd_write"
(func $fd_write (param i32 i32 i32 i32) (result i32))
)
The arguments and return values are as follows:
- 1st argument: File descriptor to write to,
1for standard output,2for standard error output - 2nd argument: Starting position for reading memory
- 3rd argument: Number of times to read memory, the value of the 2nd argument is incremented by 4 bytes each time
- 4th argument: Location to store the number of bytes written to the output, memory index value
Now that we understand the meaning of the arguments, let's explain what $hello_world is doing.
(func $hello_world (result i32)
(local $iovs i32)
(i32.store (i32.const 16) (i32.const 0)) ;; 1
(i32.store (i32.const 20) (i32.const 14)) ;; 2
(local.set $iovs (i32.const 16)) ;; 3
(call $fd_write ;; 4
(i32.const 1)
(local.get $iovs)
(i32.const 1)
(i32.const 24)
)
)
- Write
0to the 16th byte of memory0is the start of the memory data to be written - Write
14to the 20th byte of memory14is the number of bytes of memory data to be written In other words, it reads from0and writes out14bytes - Set the value
16to the declared local variable16is the value of the starting position for reading memory,fd_write()reads memory from this position - Call
fd_writeand specify to write the number of bytes written tofd 1to the 24th byte of memory
The explanation may be a bit confusing, but essentially, it arranges the value range of memory data to be written to fd, and fd_write() reads the value range and writes out the data within that range.
Now that you understand what is being done, let's proceed with the implementation.
First, create src/execution/wasi.rs and prepare a structure representing wasi_snapshot_preview1 as follows.
src/execution.rs
diff --git a/src/execution.rs b/src/execution.rs
index 5d6aec6..02686e0 100644
--- a/src/execution.rs
+++ b/src/execution.rs
@@ -2,3 +2,4 @@ pub mod import;
pub mod runtime;
pub mod store;
pub mod value;
+pub mod wasi;
src/execution/wasi.rs
#![allow(unused)] fn main() { use std::{fs::File, os::fd::FromRawFd}; #[derive(Default)] pub struct WasiSnapshotPreview1 { pub file_table: Vec<Box<File>>, } impl WasiSnapshotPreview1 { pub fn new() -> Self { unsafe { Self { file_table: vec![ Box::new(File::from_raw_fd(0)), Box::new(File::from_raw_fd(1)), Box::new(File::from_raw_fd(2)), ], } } } } }
WasiSnapshotPreview1 holds a file table, by default having stdin/stdout/stderr.
WASI has a function path_open() to open files, and when doing so, it will add to the array of file tables, although this is beyond the scope of this document, we prepare the data structure in anticipation of that.
Next, implement WasiSnapshotPreview1::invoke(...) to be able to execute WASI functions from the Wasm Runtime.
src/execution/wasi.rs
diff --git a/src/execution/wasi.rs b/src/execution/wasi.rs
index a75dc9c..b0da928 100644
--- a/src/execution/wasi.rs
+++ b/src/execution/wasi.rs
@@ -1,5 +1,8 @@
+use anyhow::Result;
use std::{fs::File, os::fd::FromRawFd};
+use super::{store::Store, value::Value};
+
#[derive(Default)]
pub struct WasiSnapshotPreview1 {
pub file_table: Vec<Box<File>>,
@@ -17,4 +20,20 @@ impl WasiSnapshotPreview1 {
}
}
}
+
+ pub fn invoke(
+ &mut self,
+ store: &mut Store,
+ func: &str,
+ args: Vec<Value>,
+ ) -> Result<Option<Value>> {
+ match func {
+ "fd_write" => self.fd_write(store, args),
+ _ => unimplemented!("{}", func),
+ }
+ }
+
+ pub fn fd_write(&mut self, store: &mut Store, args: Vec<Value>) -> Result<Option<Value>> {
+ // TODO
+ Ok(Some(0.into()))
+ }
}
WasiSnapshotPreview1::invoke(...) allows calling WASI functions based on the specified function name, and when adding more WASI functions in the future, you will need to add branches to the match statement.
Continuing, implement the process of reading data from memory and writing to fd.
src/execution/wasi.rs
diff --git a/src/execution/wasi.rs b/src/execution/wasi.rs
index b0da928..6283250 100644
--- a/src/execution/wasi.rs
+++ b/src/execution/wasi.rs
@@ -1,5 +1,5 @@
use anyhow::Result;
-use std::{fs::File, os::fd::FromRawFd};
+use std::{fs::File, io::prelude::*, os::fd::FromRawFd};
use super::{store::Store, value::Value};
@@ -34,6 +34,49 @@ impl WasiSnapshotPreview1 {
}
pub fn fd_write(&mut self, store: &mut Store, args: Vec<Value>) -> Result<Option<Value>> {
+ let args: Vec<i32> = args.into_iter().map(Into::into).collect();
+
+ let fd = args[0];
+ let mut iovs = args[1] as usize;
+ let iovs_len = args[2];
+ let rp = args[3] as usize;
+
+ let file = self
+ .file_table
+ .get_mut(fd as usize)
+ .ok_or(anyhow::anyhow!("not found fd"))?;
+
+ let memory = store
+ .memories
+ .get_mut(0)
+ .ok_or(anyhow::anyhow!("not found memory"))?;
+
+ let mut nwritten = 0;
+
+ for _ in 0..iovs_len { // 5
+ let start = memory_read(&memory.data, iovs)? as usize; // 1
+ iovs += 4;
+
+ let len: i32 = memory_read(&memory.data, iovs)?; // 2
+ iovs += 4;
+
+ let end = start + len as usize; // 3
+ nwritten += file.write(&memory.data[start..end])?; // 4
+ }
+
+ memory_write(&mut memory.data, rp, &nwritten.to_le_bytes())?; // 5
+
Ok(Some(0.into()))
}
}
+
+fn memory_read(buf: &[u8], start: usize) -> Result<i32> {
+ let end = start + 4;
+ Ok(<i32>::from_le_bytes(buf[start..end].try_into()?))
+}
+
+fn memory_write(buf: &mut [u8], start: usize, data: &[u8]) -> Result<()> {
+ let end = start + data.len();
+ buf[start..end].copy_from_slice(data);
+ Ok(())
+}
The process in WasiSnapshotPreview1::fd_write(...) may be a bit unclear, so let's explain it while showing the byte sequence.
First, let's take a look at the memory state when WasiSnapshotPreview1::fd_write(...) is called.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | ... |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| H | e | l | l | o | , | W | o | r | l | d | ! | \n | 0 | 0 | 0 | 0 | 0 | 0 | 14 | ... |
First, we retrieve the starting position of the data to be written at the position specified by iovs, which is 16.
Since iovs is 16, the value is 0, which was placed using (i32.store (i32.const 16) (i32.const 0)).
Since memory is aligned by 4 bytes, we add +4 to iovs to get the length of the data to be written at step 2.
The 14 at position 20 is the value placed using (i32.store (i32.const 20) (i32.const 14)).
Now that we know the length of the data to be written, we calculate the range of memory data to be extracted (0-14 bytes) at step 3 and write that byte sequence to fd at step 4.
This process is repeated for the number of times specified by iovs_len, and at step 5, the total number of bytes written is placed at the memory address specified by rp.
After step 5, the memory state will be as follows:
| ... | 14 | 15 | 16 | 17 | 18 | 19 | 20 | ... | 24 | ... |
|---|---|---|---|---|---|---|---|---|---|---|
| ... | 0 | 0 | 0 | 0 | 0 | 0 | 14 | ... | 13 | ... |
With the implementation of WasiSnapshotPreview1::fd_write(...), we can now proceed to call it.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 4fb8807..6fba7e7 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -4,6 +4,7 @@ use super::{
import::Import,
store::{ExternalFuncInst, FuncInst, InternalFuncInst, Store},
value::Value,
+ wasi::WasiSnapshotPreview1,
};
use crate::binary::{
instruction::Instruction,
@@ -27,6 +28,7 @@ pub struct Runtime {
pub stack: Vec<Value>,
pub call_stack: Vec<Frame>,
pub import: Import,
+ pub wasi: Option<WasiSnapshotPreview1>,
}
impl Runtime {
@@ -120,6 +122,13 @@ impl Runtime {
let args = self
.stack
.split_off(self.stack.len() - func.func_type.params.len());
+
+ if func.module == "wasi_snapshot_preview1" {
+ if let Some(wasi) = &mut self.wasi {
+ return wasi.invoke(&mut self.store, &func.func, args);
+ }
+ }
+
let module = self
.import
.get_mut(&func.module)
Next, ensure that when creating a Runtime, an instance of WasiSnapshotPreview1 can be passed.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 6fba7e7..573539f 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -41,6 +41,19 @@ impl Runtime {
})
}
+ pub fn instantiate_with_wasi(
+ wasm: impl AsRef<[u8]>,
+ wasi: WasiSnapshotPreview1,
+ ) -> Result<Self> {
+ let module = Module::new(wasm.as_ref())?;
+ let store = Store::new(module)?;
+ Ok(Self {
+ store,
+ wasi: Some(wasi),
+ ..Default::default()
+ })
+ }
+
pub fn add_import(
&mut self,
module_name: impl Into<String>,
Finally, add the process to read and execute the compiled hello_world.wasm from hello_world.wat using wat2wasm to main.rs.
src/main.rs
diff --git a/src/main.rs b/src/main.rs
index e7a11a9..fd8f527 100644
--- a/src/main.rs
+++ b/src/main.rs
@@ -1,3 +1,10 @@
-fn main() {
- println!("Hello, world!");
+use anyhow::Result;
+use tinywasm::execution::{runtime::Runtime, wasi::WasiSnapshotPreview1};
+
+fn main() -> Result<()> {
+ let wasi = WasiSnapshotPreview1::new();
+ let wasm = include_bytes!("./fixtures/hello_world.wasm");
+ let mut runtime = Runtime::instantiate_with_wasi(wasm, wasi)?;
+ runtime.call("_start", vec![]).unwrap();
+ Ok(())
}
If the implementation is correct, Hello, World! should be output as follows:
$ cargo run -q
Hello, World!
Summary
With this, a small Wasm Runtime capable of outputting Hello, World! has been completed.
Although there was much to learn, the tasks themselves may not have been as difficult as initially thought.
The instructions implemented in this book are minimal, but they are sufficient to understand the mechanism of a functioning Wasm Runtime at the implementation level.
If you are interested in challenging yourself to implement a complete Wasm Runtime, I encourage you to read the specifications and give it a try.
It may be challenging, but the sense of accomplishment when it runs successfully is truly rewarding.
For reference, by implementing version 1 instructions and a certain level of WASI, you can achieve the following:
https://zenn.dev/skanehira/articles/2023-09-18-rust-wasm-runtime-containerd https://zenn.dev/skanehira/articles/2023-12-02-wasm-risp
Lastly, I would like to express my gratitude for reading this book. If you found it valuable, please consider sharing it on social media platforms.
Extra edition implementation fibonacci execution
In this chapter, we will add additional implementations to make the Fibonacci function executable as an extra edition.
For those who find the output of Hello, World! a bit unsatisfying, this will be a perfect dessert.
(module
(func $fib (export "fib") (param $n i32) (result i32)
(if
(i32.lt_s (local.get $n) (i32.const 2))
(return (i32.const 1))
)
(return
(i32.add
(call $fib (i32.sub (local.get $n) (i32.const 2)))
(call $fib (i32.sub (local.get $n) (i32.const 1)))
)
)
)
)
About Binary Structure
We will explain what the binary structure looks like when there are flow control instructions like if.
The following is the binary structure of the function part.
; function body 0
0000020: 1d ; func body size
0000021: 00 ; local decl count
0000022: 20 ; local.get
0000023: 00 ; local index
0000024: 41 ; i32.const
0000025: 02 ; i32 literal
0000026: 48 ; i32.lt_s
0000027: 04 ; if
0000028: 40 ; void
0000029: 41 ; i32.const
000002a: 01 ; i32 literal
000002b: 0f ; return
000002c: 0b ; end
000002d: 20 ; local.get
000002e: 00 ; local index
000002f: 41 ; i32.const
0000030: 02 ; i32 literal
0000031: 6b ; i32.sub
0000032: 10 ; call
0000033: 00 ; function index
0000034: 20 ; local.get
0000035: 00 ; local index
0000036: 41 ; i32.const
0000037: 01 ; i32 literal
0000038: 6b ; i32.sub
0000039: 10 ; call
000003a: 00 ; function index
000003b: 6a ; i32.add
000003c: 0f ; return
000003d: 0b ; end
In the above, the following instructions are used for the unimplemented part.
| Instruction | Description |
|---|---|
i32.sub | Pop two values from the stack and subtract them |
i32.lt_s | Pop two values from the stack and compare with < |
if | Pop one value from the stack, evaluate, and process branching |
return | Return to the caller |
Let's first look at the instruction sequence for the if part.
(if
(i32.lt_s (local.get $n) (i32.const 2))
(return (i32.const 1))
)
The instruction sequence is as follows.
0000022: 20 ; local.get
0000023: 00 ; local index
0000024: 41 ; i32.const
0000025: 02 ; i32 literal
0000026: 48 ; i32.lt_s
0000027: 04 ; if
0000028: 40 ; void
0000029: 41 ; i32.const
000002a: 01 ; i32 literal
000002b: 0f ; return
000002c: 0b ; end
It pushes the argument and 2 onto the stack, uses i32.lt_s to compare with <, and pushes the result onto the stack.
By the way, in Wasm, if the comparison result is 0, it is false; otherwise, it is true.
Next, after popping the comparison result from the stack, if it is true, it proceeds; if it is false, it jumps to end.
Following if is void, but in Wasm, if can return a value, and void means no return value.
This part becomes the operand of the if instruction.
In this case, if it is true, it pushes 1 onto the stack and returns to the caller using return.
Next, let's look at the part after return.
(return
(i32.add
(call $fib (i32.sub (local.get $n) (i32.const 2)))
(call $fib (i32.sub (local.get $n) (i32.const 1)))
)
)
The instruction sequence is as follows.
000002d: 20 ; local.get
000002e: 00 ; local index
000002f: 41 ; i32.const
0000030: 02 ; i32 literal
0000031: 6b ; i32.sub
0000032: 10 ; call
0000033: 00 ; function index
0000034: 20 ; local.get
0000035: 00 ; local index
0000036: 41 ; i32.const
0000037: 01 ; i32 literal
0000038: 6b ; i32.sub
0000039: 10 ; call
000003a: 00 ; function index
000003b: 6a ; i32.add
000003c: 0f ; return
000003d: 0b ; end
It might be a bit hard to understand, so to clarify which instruction corresponds to which operation, it looks like this.
local.get ┐ ┐ ┐
local index │ (i32.sub │ │
i32.const ├ (local.get $n) ├ (call $fib ...) │
i32 literal │ (i32.const 2)) │ │
i32.sub ┘ │ │
call ┌──────────────────┘ │
function index ┘ ├ (return (i32.add ...))
local.get ┐ ┐ │
local index │ (i32.sub │ │
i32.const ├ (local.get $n) ├ (call $fib ...) │
i32 literal │ (i32.const 1)) │ │
i32.sub ┘ │ │
call ┌──────────────────┘ │
function index ┘ │
i32.add ┌─────────────────┘
return ┌──────────────────┘
end ┘
Instruction Decoding Implementation
Now that we understand the binary structure, let's implement it.
First, add the opcode.
src/binary/opcode.rs
diff --git a/src/binary/opcode.rs b/src/binary/opcode.rs
index 1e0931b..165a563 100644
--- a/src/binary/opcode.rs
+++ b/src/binary/opcode.rs
@@ -2,11 +2,15 @@ use num_derive::FromPrimitive;
#[derive(Debug, FromPrimitive, PartialEq)]
pub enum Opcode {
+ If = 0x04,
End = 0x0B,
+ Return = 0x0F,
LocalGet = 0x20,
LocalSet = 0x21,
I32Store = 0x36,
I32Const = 0x41,
+ I32LtS = 0x48,
I32Add = 0x6A,
+ I32Sub = 0x6B,
Call = 0x10,
}
Next, define the Block used in the if instruction.
src/binary/types.rs
diff --git a/src/binary/types.rs b/src/binary/types.rs
index bff2cd4..474c296 100644
--- a/src/binary/types.rs
+++ b/src/binary/types.rs
@@ -66,3 +66,23 @@ pub struct Data {
pub offset: u32,
pub init: Vec<u8>,
}
+
+#[derive(Debug, Clone, PartialEq, Eq)]
+pub struct Block {
+ pub block_type: BlockType,
+}
+
+#[derive(Debug, Clone, PartialEq, Eq)]
+pub enum BlockType {
+ Void,
+ Value(Vec<ValueType>),
+}
+
+impl BlockType {
+ pub fn result_count(&self) -> usize {
+ match self {
+ Self::Void => 0,
+ Self::Value(value_types) => value_types.len(),
+ }
+ }
+}
In Wasm, the if instruction represents the number of return values with Block, where Block::Void means no return value, and Block::Value means there is a return value.
Since there are no return values in this case, it will mostly be Block::Void.
Additionally, besides the If instruction, there are also block and loop instructions, which similarly have operands for return values, so Block is used for those as well.
Next, define the instructions.
src/binary/instruction.rs
diff --git a/src/binary/instruction.rs b/src/binary/instruction.rs
index 326db0a..8595bdc 100644
--- a/src/binary/instruction.rs
+++ b/src/binary/instruction.rs
@@ -1,10 +1,16 @@
+use super::types::Block;
+
#[derive(Debug, Clone, PartialEq, Eq)]
pub enum Instruction {
+ If(Block),
End,
+ Return,
LocalGet(u32),
LocalSet(u32),
I32Store { align: u32, offset: u32 },
I32Const(i32),
+ I32Lts,
I32Add,
+ I32Sub,
Call(u32),
}
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index 3fdd323..82e250f 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -3,8 +3,8 @@ use super::{
opcode::Opcode,
section::{Function, SectionCode},
types::{
- Data, Export, ExportDesc, FuncType, FunctionLocal, Import, ImportDesc, Limits, Memory,
- ValueType,
+ Block, BlockType, Data, Export, ExportDesc, FuncType, FunctionLocal, Import, ImportDesc,
+ Limits, Memory, ValueType,
},
};
use nom::{
@@ -213,6 +213,11 @@ fn decode_instructions(input: &[u8]) -> IResult<&[u8], Instruction> {
let (input, byte) = le_u8(input)?;
let op = Opcode::from_u8(byte).unwrap_or_else(|| panic!("invalid opcode: {:X}", byte));
let (rest, inst) = match op {
+ Opcode::If => {
+ let (rest, block) = decode_block(input)?;
+ (rest, Instruction::If(block))
+ }
+ Opcode::Return => (input, Instruction::Return),
Opcode::LocalGet => {
let (rest, idx) = leb128_u32(input)?;
(rest, Instruction::LocalGet(idx))
@@ -230,7 +235,9 @@ fn decode_instructions(input: &[u8]) -> IResult<&[u8], Instruction> {
let (rest, value) = leb128_i32(input)?;
(rest, Instruction::I32Const(value))
}
+ Opcode::I32LtS => (input, Instruction::I32Lts),
Opcode::I32Add => (input, Instruction::I32Add),
+ Opcode::I32Sub => (input, Instruction::I32Sub),
Opcode::End => (input, Instruction::End),
Opcode::Call => {
let (rest, idx) = leb128_u32(input)?;
@@ -330,6 +337,18 @@ fn deocde_data_section(input: &[u8]) -> IResult<&[u8], Vec<Data>> {
Ok((input, data))
}
+fn decode_block(input: &[u8]) -> IResult<&[u8], Block> {
+ let (input, byte) = le_u8(input)?;
+
+ let block_type = if byte == 0x40 {
+ BlockType::Void
+ } else {
+ BlockType::Value(vec![byte.into()])
+ };
+
+ Ok((input, Block { block_type }))
+}
+
fn decode_name(input: &[u8]) -> IResult<&[u8], String> {
let (input, size) = leb128_u32(input)?;
let (input, name) = take(size)(input)?;
decode_block(...) is a function that generates Block, and if the next after if is 0x40, it means no return value, otherwise it becomes the value of the number of return values.
In version 1, since only one return value can be returned, it effectively becomes 1.
For the part of implementing instructions, let's leave it as TODO for now.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 573539f..0ebce7c 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -223,6 +223,7 @@ impl Runtime {
}
}
}
+ _ => todo!(),
}
}
Ok(())
Now you can write tests for decoding, ensuring that the implementation is correct.
src/binary/module.rs
diff --git a/src/binary/module.rs b/src/binary/module.rs
index 82e250f..357da5b 100644
--- a/src/binary/module.rs
+++ b/src/binary/module.rs
@@ -365,8 +365,8 @@ mod tests {
module::Module,
section::Function,
types::{
- Data, Export, ExportDesc, FuncType, FunctionLocal, Import, ImportDesc, Limits, Memory,
- ValueType,
+ Block, BlockType, Data, Export, ExportDesc, FuncType, FunctionLocal, Import,
+ ImportDesc, Limits, Memory, ValueType,
},
};
use anyhow::Result;
@@ -652,4 +652,51 @@ mod tests {
);
Ok(())
}
+
+ #[test]
+ fn decode_fib() -> Result<()> {
+ let wasm = wat::parse_file("src/fixtures/fib.wat")?;
+ let module = Module::new(&wasm)?;
+ assert_eq!(
+ module,
+ Module {
+ type_section: Some(vec![FuncType {
+ params: vec![ValueType::I32],
+ results: vec![ValueType::I32],
+ }]),
+ function_section: Some(vec![0]),
+ code_section: Some(vec![Function {
+ locals: vec![],
+ code: vec![
+ Instruction::LocalGet(0),
+ Instruction::I32Const(2),
+ Instruction::I32Lts,
+ Instruction::If(Block {
+ block_type: BlockType::Void
+ }),
+ Instruction::I32Const(1),
+ Instruction::Return,
+ Instruction::End,
+ Instruction::LocalGet(0),
+ Instruction::I32Const(2),
+ Instruction::I32Sub,
+ Instruction::Call(0),
+ Instruction::LocalGet(0),
+ Instruction::I32Const(1),
+ Instruction::I32Sub,
+ Instruction::Call(0),
+ Instruction::I32Add,
+ Instruction::Return,
+ Instruction::End,
+ ],
+ }]),
+ export_section: Some(vec![Export {
+ name: "fib".into(),
+ desc: ExportDesc::Func(0),
+ }]),
+ ..Default::default()
+ }
+ );
+ Ok(())
+ }
}
running 21 tests
test binary::module::tests::decode_func_param ... ok
test binary::module::tests::decode_simplest_func ... ok
test binary::module::tests::decode_memory ... ok
test binary::module::tests::decode_i32_store ... ok
test binary::module::tests::decode_data ... ok
test binary::module::tests::decode_simplest_module ... ok
test binary::module::tests::decode_fib ... ok
test binary::module::tests::decode_func_local ... ok
test binary::module::tests::decode_func_add ... ok
test execution::runtime::tests::execute_i32_add ... ok
test execution::runtime::tests::not_found_export_function ... ok
test binary::module::tests::decode_func_call ... ok
test execution::runtime::tests::func_call ... ok
test binary::module::tests::decode_import ... ok
test execution::runtime::tests::call_imported_func ... ok
test execution::runtime::tests::not_found_imported_func ... ok
test execution::store::test::init_memory ... ok
test execution::runtime::tests::i32_const ... ok
test execution::runtime::tests::i32_store ... ok
test execution::runtime::tests::local_set ... ok
test execution::runtime::tests::fib ... ok
Implementation of Commands
Now that the decoding process is complete, let's move on to implementing the commands.
We will start by implementing the simplest command, i32.sub.
Implementation of i32.sub
First, we will implement std::ops::Sub to enable subtraction between Value instances.
src/execution/value.rs
diff --git a/src/execution/value.rs b/src/execution/value.rs
index 21d364d..6a7820f 100644
--- a/src/execution/value.rs
+++ b/src/execution/value.rs
@@ -35,3 +35,14 @@ impl std::ops::Add for Value {
}
}
}
+
+impl std::ops::Sub for Value {
+ type Output = Self;
+ fn sub(self, rhs: Self) -> Self::Output {
+ match (self, rhs) {
+ (Value::I32(left), Value::I32(right)) => Value::I32(left - right),
+ (Value::I64(left), Value::I64(right)) => Value::I64(left - right),
+ _ => panic!("type mismatch"),
+ }
+ }
+}
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 0ebce7c..a2aabe9 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -209,6 +209,13 @@ impl Runtime {
let result = left + right;
self.stack.push(result);
}
+ Instruction::I32Sub => {
+ let (Some(right), Some(left)) = (self.stack.pop(), self.stack.pop()) else {
+ bail!("not found any value in the stack");
+ };
+ let result = left - right;
+ self.stack.push(result);
+ }
Instruction::Call(idx) => {
let Some(func) = self.store.funcs.get(*idx as usize) else {
bail!("not found func");
Add tests to ensure the implementation is correct.
(module
(func (export "sub") (param i32 i32) (result i32)
(local.get 0)
(local.get 1)
i32.sub
)
)
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index a2aabe9..4726a24 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -353,4 +353,13 @@ mod tests {
assert_eq!(memory[0], 42);
Ok(())
}
+
+ #[test]
+ fn i32_sub() -> Result<()> {
+ let wasm = wat::parse_file("src/fixtures/func_sub.wat")?;
+ let mut runtime = Runtime::instantiate(wasm)?;
+ let result = runtime.call("sub", vec![Value::I32(10), Value::I32(5)])?;
+ assert_eq!(result, Some(Value::I32(5)));
+ Ok(())
+ }
}
running 21 tests
test binary::module::tests::decode_func_local ... ok
test binary::module::tests::decode_simplest_func ... ok
test binary::module::tests::decode_func_param ... ok
test binary::module::tests::decode_memory ... ok
test binary::module::tests::decode_data ... ok
test binary::module::tests::decode_fib ... ok
test binary::module::tests::decode_i32_store ... ok
test binary::module::tests::decode_import ... ok
test binary::module::tests::decode_func_add ... ok
test binary::module::tests::decode_simplest_module ... ok
test binary::module::tests::decode_func_call ... ok
test execution::runtime::tests::execute_i32_add ... ok
test execution::runtime::tests::call_imported_func ... ok
test execution::runtime::tests::func_call ... ok
test execution::runtime::tests::i32_sub ... ok
test execution::runtime::tests::i32_store ... ok
test execution::runtime::tests::not_found_export_function ... ok
test execution::runtime::tests::not_found_imported_func ... ok
test execution::runtime::tests::i32_const ... ok
test execution::runtime::tests::local_set ... ok
test execution::store::test::init_memory ... ok
Implementation of i32.lt_s
The lt_s command compares two i32 values using <. We will first implement std::cmp::Ordering to enable this comparison. Additionally, since the result of the comparison will be a bool, we will implement From<bool> for Value to push this result onto the stack.
/src/execution/value.rs
diff --git a/src/execution/value.rs b/src/execution/value.rs
index 6a7820f..eee47ac 100644
--- a/src/execution/value.rs
+++ b/src/execution/value.rs
@@ -1,3 +1,5 @@
+use std::cmp::Ordering;
+
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
pub enum Value {
I32(i32),
@@ -19,6 +21,12 @@ impl From<Value> for i32 {
}
}
+impl From<bool> for Value {
+ fn from(value: bool) -> Self {
+ Value::I32(if value { 1 } else { 0 })
+ }
+}
+
impl From<i64> for Value {
fn from(value: i64) -> Self {
Value::I64(value)
@@ -46,3 +54,13 @@ impl std::ops::Sub for Value {
}
}
}
+
+impl PartialOrd for Value {
+ fn partial_cmp(&self, other: &Self) -> Option<Ordering> {
+ match (self, other) {
+ (Value::I32(a), Value::I32(b)) => a.partial_cmp(b),
+ (Value::I64(a), Value::I64(b)) => a.partial_cmp(b),
+ _ => panic!("type mismatch"),
+ }
+ }
+}
Next, we will implement the command and add tests to ensure the implementation is correct.
/src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 4726a24..c163669 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -216,6 +216,13 @@ impl Runtime {
let result = left - right;
self.stack.push(result);
}
+ Instruction::I32Lts => {
+ let (Some(right), Some(left)) = (self.stack.pop(), self.stack.pop()) else {
+ bail!("not found any value in the stack");
+ };
+ let result = left < right;
+ self.stack.push(result.into());
+ }
Instruction::Call(idx) => {
let Some(func) = self.store.funcs.get(*idx as usize) else {
bail!("not found func");
(module
(func (export "lts") (param i32 i32) (result i32)
(local.get 0)
(local.get 1)
i32.lt_s
)
)
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index c163669..8d9ff62 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -369,4 +369,13 @@ mod tests {
assert_eq!(result, Some(Value::I32(5)));
Ok(())
}
+
+ #[test]
+ fn i32_lts() -> Result<()> {
+ let wasm = wat::parse_file("src/fixtures/func_lts.wat")?;
+ let mut runtime = Runtime::instantiate(wasm)?;
+ let result = runtime.call("lts", vec![Value::I32(10), Value::I32(5)])?;
+ assert_eq!(result, Some(Value::I32(0)));
+ Ok(())
+ }
}
running 10 tests
test execution::runtime::tests::i32_const ... ok
test execution::runtime::tests::not_found_imported_func ... ok
test execution::runtime::tests::func_call ... ok
test execution::runtime::tests::i32_sub ... ok
test execution::runtime::tests::local_set ... ok
test execution::runtime::tests::call_imported_func ... ok
test execution::runtime::tests::i32_store ... ok
test execution::runtime::tests::execute_i32_add ... ok
test execution::runtime::tests::not_found_export_function ... ok
test execution::runtime::tests::i32_lts ... ok
Implementation of if/return
Next, we will implement flow control commands for if.
First, we will add a Label. Label is used for controlling blocks that have return values, such as if or block.
For example, in the case of if, there may be an else branch (which we are not implementing in this case). If the evaluation result is false, we need to jump to the else command, and this behavior is achieved using Label.
Additionally, when exiting the if block, we need to rewind the stack, which is also achieved using Label.
src/execution/value.rs
diff --git a/src/execution/value.rs b/src/execution/value.rs
index eee47ac..5c49e06 100644
--- a/src/execution/value.rs
+++ b/src/execution/value.rs
@@ -64,3 +64,16 @@ impl PartialOrd for Value {
}
}
}
+
+#[derive(Debug, Clone, PartialEq)]
+pub enum LabelKind {
+ If,
+}
+
+#[derive(Debug, Clone)]
+pub struct Label {
+ pub kind: LabelKind,
+ pub pc: usize,
+ pub sp: usize,
+ pub arity: usize,
+}
Next, we will proceed with the command processing implementation.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 8d9ff62..f0d90f8 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -3,13 +3,16 @@ use std::mem::size_of;
use super::{
import::Import,
store::{ExternalFuncInst, FuncInst, InternalFuncInst, Store},
- value::Value,
+ value::{LabelKind, Value},
wasi::WasiSnapshotPreview1,
};
-use crate::binary::{
- instruction::Instruction,
- module::Module,
- types::{ExportDesc, ValueType},
+use crate::{
+ binary::{
+ instruction::Instruction,
+ module::Module,
+ types::{ExportDesc, ValueType},
+ },
+ execution::value::Label,
};
use anyhow::{anyhow, bail, Result};
@@ -19,6 +22,7 @@ pub struct Frame {
pub sp: usize,
pub insts: Vec<Instruction>,
pub arity: usize,
+ pub labels: Vec<Label>,
pub locals: Vec<Value>,
}
@@ -107,6 +111,7 @@ impl Runtime {
insts: func.code.body.clone(),
arity,
locals,
+ labels: vec![],
};
self.call_stack.push(frame);
@@ -165,6 +170,24 @@ impl Runtime {
};
match inst {
+ Instruction::If(block) => {
+ let cond = self // 1
+ .stack
+ .pop()
+ .ok_or(anyhow!("not found value in the stack"))?;
+
+ let next_pc = get_end_address(&frame.insts, frame.pc as usize)?; // 2
+ if cond == Value::I32(0) { // 3
+ frame.pc = next_pc as isize
+ }
+
+ let label = Label {
+ kind: LabelKind::If,
+ pc: next_pc,
+ sp: self.stack.len(),
+ arity: block.block_type.result_count(),
+ };
+ frame.labels.push(label);
+ }
Instruction::End => {
let Some(frame) = self.call_stack.pop() else {
bail!("not found frame");
@@ -249,6 +272,30 @@ impl Runtime {
}
}
+pub fn get_end_address(insts: &[Instruction], pc: usize) -> Result<usize> {
+ let mut pc = pc;
+ let mut depth = 0;
+ loop {
+ pc += 1;
+ let inst = insts.get(pc).ok_or(anyhow!("not found instructions"))?;
+ match inst {
+ Instruction::If(_) => { // 3
+ depth += 1;
+ }
+ Instruction::End => {
+ if depth == 0 {
+ return Ok(pc);
+ } else {
+ depth -= 1;
+ }
+ }
+ _ => {
+ // do nothing
+ }
+ }
+ }
+}
+
pub fn stack_unwind(stack: &mut Vec<Value>, sp: usize, arity: usize) -> Result<()> {
if arity > 0 {
let Some(value) = stack.pop() else {
In the if command, we are doing the following:
- Pop a value from the stack for evaluation.
- Calculate
pcat the end ofif - If it is
false, the next instruction will beend, so updateframe.pctopccalculated in step 2.- If it is
true, there is no need to adjust thepc; we simply push the label and continue processing the next command.
- If it is
ifmay be nested, so in that case, control withdepth
It is worth noting that the end of an if command is similar to the end of a function, marked by the end command. This is also the case for block and loop commands.
Therefore, when processing the end command, we need to determine whether it is the end of an if/block/loop or the end of a function. This determination is simple: if the label stack is empty, it signifies the end of a function.
The actual implementation is as follows.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index f0d90f8..23ee5dc 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -188,6 +188,21 @@ impl Runtime {
};
frame.labels.push(label);
}
+ Instruction::End => match frame.labels.pop() {
+ Some(label) => {
+ let Label { pc, sp, arity, .. } = label;
+ frame.pc = pc as isize;
+ stack_unwind(&mut self.stack, sp, arity)?;
+ }
+ None => {
+ let frame = self
+ .call_stack
+ .pop()
+ .ok_or(anyhow!("not found value in th stack"))?;
+ let Frame { sp, arity, .. } = frame;
+ stack_unwind(&mut self.stack, sp, arity)?;
+ }
+ },
Instruction::Return => {
let Some(frame) = self.call_stack.pop() else {
bail!("not found frame");
@@ -260,7 +275,6 @@ impl Runtime {
}
}
}
- _ => todo!(),
}
}
Ok(())
If a label exists, it signifies the end of an if command, and we adjust the pc and stack accordingly. The reason for adjusting the stack is that there may be values left on the stack from processing within the if block.
For example, if the if evaluates to true and only pushes 3 onto the stack, there will be values left on the stack that need to be rewound.
(if
(i32.const 1)
(i32.const 3)
)
With this, the implementation for running the Fibonacci function is complete. Now, let's add tests to ensure that the implementation is correct.
src/execution/runtime.rs
diff --git a/src/execution/runtime.rs b/src/execution/runtime.rs
index 23ee5dc..291353f 100644
--- a/src/execution/runtime.rs
+++ b/src/execution/runtime.rs
@@ -439,4 +439,29 @@ mod tests {
assert_eq!(result, Some(Value::I32(0)));
Ok(())
}
+
+ #[test]
+ fn fib() -> Result<()> {
+ let wasm = wat::parse_file("src/fixtures/fib.wat")?;
+ let mut runtime = Runtime::instantiate(wasm)?;
+ let tests = vec![
+ (1, 1),
+ (2, 2),
+ (3, 3),
+ (4, 5),
+ (5, 8),
+ (6, 13),
+ (7, 21),
+ (8, 34),
+ (9, 55),
+ (10, 89),
+ ];
+
+ for (arg, want) in tests {
+ let args = vec![Value::I32(arg)];
+ let result = runtime.call("fib", args)?;
+ assert_eq!(result, Some(Value::I32(want)));
+ }
+ Ok(())
+ }
}
running 23 tests
test binary::module::tests::decode_fib ... ok
test binary::module::tests::decode_i32_store ... ok
test binary::module::tests::decode_import ... ok
test binary::module::tests::decode_simplest_func ... ok
test binary::module::tests::decode_func_param ... ok
test binary::module::tests::decode_func_add ... ok
test binary::module::tests::decode_data ... ok
test binary::module::tests::decode_memory ... ok
test binary::module::tests::decode_func_local ... ok
test binary::module::tests::decode_func_call ... ok
test binary::module::tests::decode_simplest_module ... ok
test execution::runtime::tests::execute_i32_add ... ok
test execution::runtime::tests::call_imported_func ... ok
test execution::runtime::tests::i32_const ... ok
test execution::runtime::tests::i32_lts ... ok
test execution::runtime::tests::func_call ... ok
test execution::runtime::tests::i32_store ... ok
test execution::runtime::tests::not_found_export_function ... ok
test execution::runtime::tests::i32_sub ... ok
test execution::runtime::tests::local_set ... ok
test execution::store::test::init_memory ... ok
test execution::runtime::tests::not_found_imported_func ... ok
test execution::runtime::tests::fib ... ok
Summary
With this, a Wasm Runtime capable of running the Fibonacci function has been created.
The implementation of control instructions was quite interesting, wasn't it?
If you have any requests such as wanting to run something like this, please feel free to write it in an issue. I would be happy to consider writing about it when I feel like it.